自定义分段
每次上传 XML、HTML、MD 或任何其他不含键值结构的源文件时,系统都会使用预定义的分段规则 (SRX 2.0) 进行自动内容分段。 但是,有时默认分段规则对源文件的分段结果可能与预期不符。
在这种情况下,您可以使用 SRX 2.0 标准为每个源文件单独定义自己的分段规则。
您可以在 Sources > Files 中更改分段。
- 打开您要调整分段规则的项目,然后转到 Sources > Files。
- 在所需文件上点击 (或右键单击),然后选择设置。
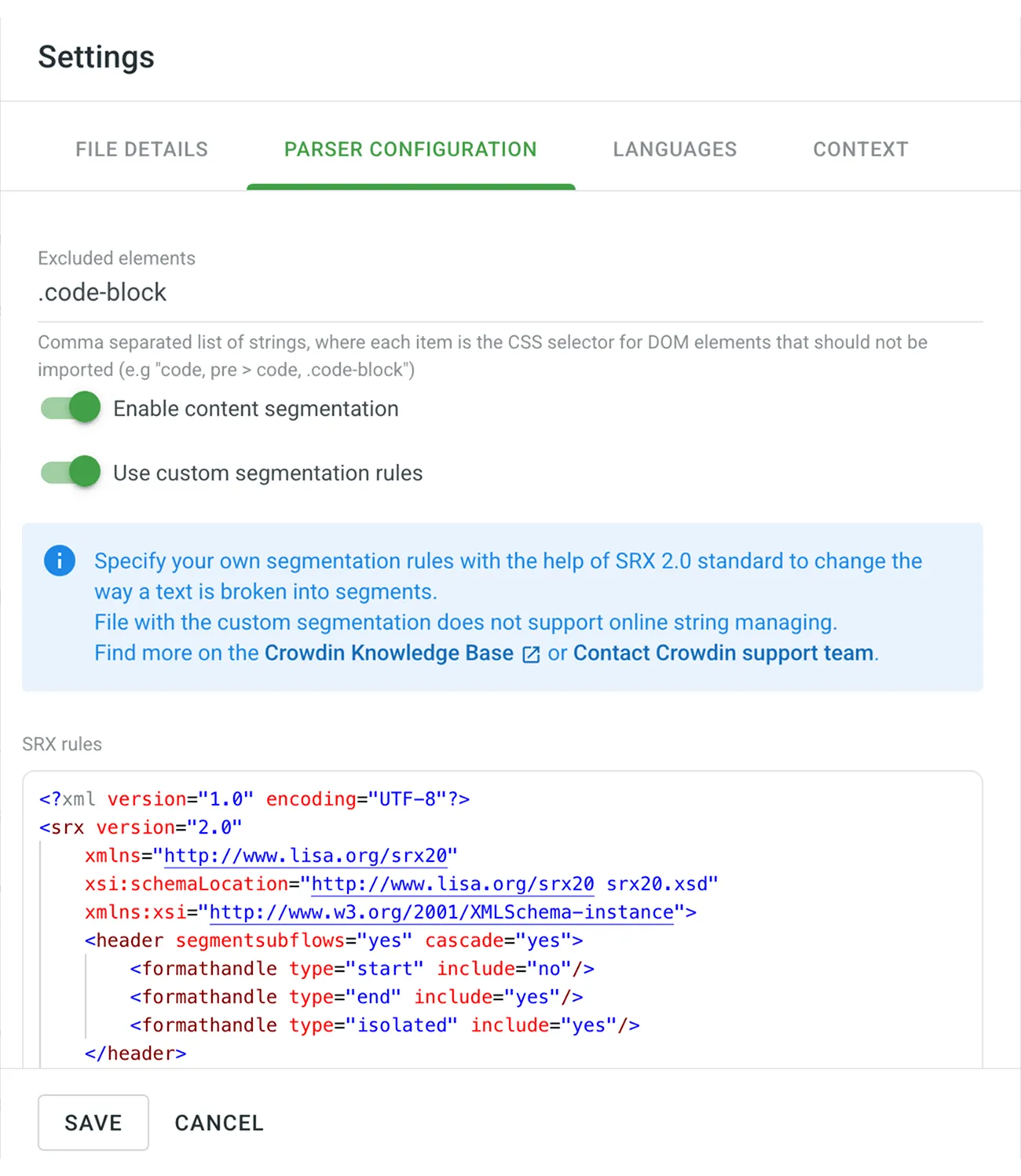
- 在弹出的对话框中,切换到 Parser configuration 选项卡。
- 在排除元素字段中,指定所有不应导入的元素。
- 选择 Enable content segmentation 和 Use custom segmentation rules。
- 粘贴您的 SRX 分段规则,然后单击 Save。
保存新的分段规则后,您的源文件将自动重新导入,并按照这些新规则进行分段。
典型的 SRX 文件类似于以下内容:
<?xml version="1.0" encoding="UTF-8"?><srx version="2.0" xmlns="http://www.lisa.org/srx20" xsi:schemaLocation="http://www.lisa.org/srx20 srx20.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <header segmentsubflows="yes" cascade="yes"> <formathandle type="start" include="no"/> <formathandle type="end" include="yes"/> <formathandle type="isolated" include="yes"/> </header> <body> <languagerules> <languagerule languagerulename="Default"> <!-- Common rules for most languages --> <rule break="no"> <beforebreak>^\s*[0-9]+\.</beforebreak> <afterbreak>\s</afterbreak> </rule> <rule break="yes"> <afterbreak>\n</afterbreak> </rule> <rule break="yes"> <beforebreak>[\.\?!]+</beforebreak> <afterbreak>\s</afterbreak> </rule> </languagerule> </languagerules> <maprules> <!-- List exceptions first --> <languagemap languagepattern="[Ee][Nn].*" languagerulename="English"/> <languagemap languagepattern="[Ff][Rr].*" languagerulename="French"/> <!-- Japanese breaking rules --> <languagemap languagepattern="[Jj][Aa].*" languagerulename="Japanese"/> <!-- Common breaking rules --> <languagemap languagepattern=".*" languagerulename="Default"/> </maprules> </body></srx>通常,句号用作句子分隔符。 但对于某些亚洲语言,情况并非如此。 例如,中文中典型的句子分隔符是表意文字句号(。)。 对于此类情况,您可以使用以下规则集:
<rule break="yes"> <beforebreak>[\x3002]+</beforebreak> <afterbreak></afterbreak></rule>在以下简单示例中,我们将说明一种情况:当需要将一段文本分段为两个(或更多)字符串时该如何处理。
使用默认分段规则的文本:
这是示例句子的第一部分,这是第二部分。
使用新分段规则的文本:
这是示例句子的第一部分
这是第二部分。
对于这种特定情况,以下规则集将把初始句子拆分为两个部分:
<rule break="yes"> <beforebreak>sentence</beforebreak> <afterbreak>\u0020</afterbreak></rule>可以借助 Ratel 等工具来创建和维护 SRX 分段规则。 它提供可视化界面,您可以在其中从头创建分段规则或编辑现有规则。
分段规则生成器在您的 Crowdin 项目中创建和测试新的分段规则。
SRX PlaygroundAI 驱动的 SRX 规则编辑器。
感谢您的反馈!