Translation Memory
A Translation Memory (TM) is a database that stores translation units, which are segments of source text paired with their corresponding translations in different languages. It improves and speeds up the translation process by providing suggestions for identical or similar strings in your projects.
A project TM is created automatically for each Crowdin Enterprise project. By default, each translation made within the project is automatically added to the project’s TM. This behavior can be customized in the project settings to save only approved translations.
In addition to the project TMs that are automatically created with each project, you can create separate TMs and populate them with content by uploading your existing TMs in TMX, XLSX, or CSV formats. These TMs can then be assigned to the relevant projects as needed.
To create a TM, follow these steps:
- Open your organization’s Workspace and select Translation memories on the left sidebar.
- At the bottom right, click Create.
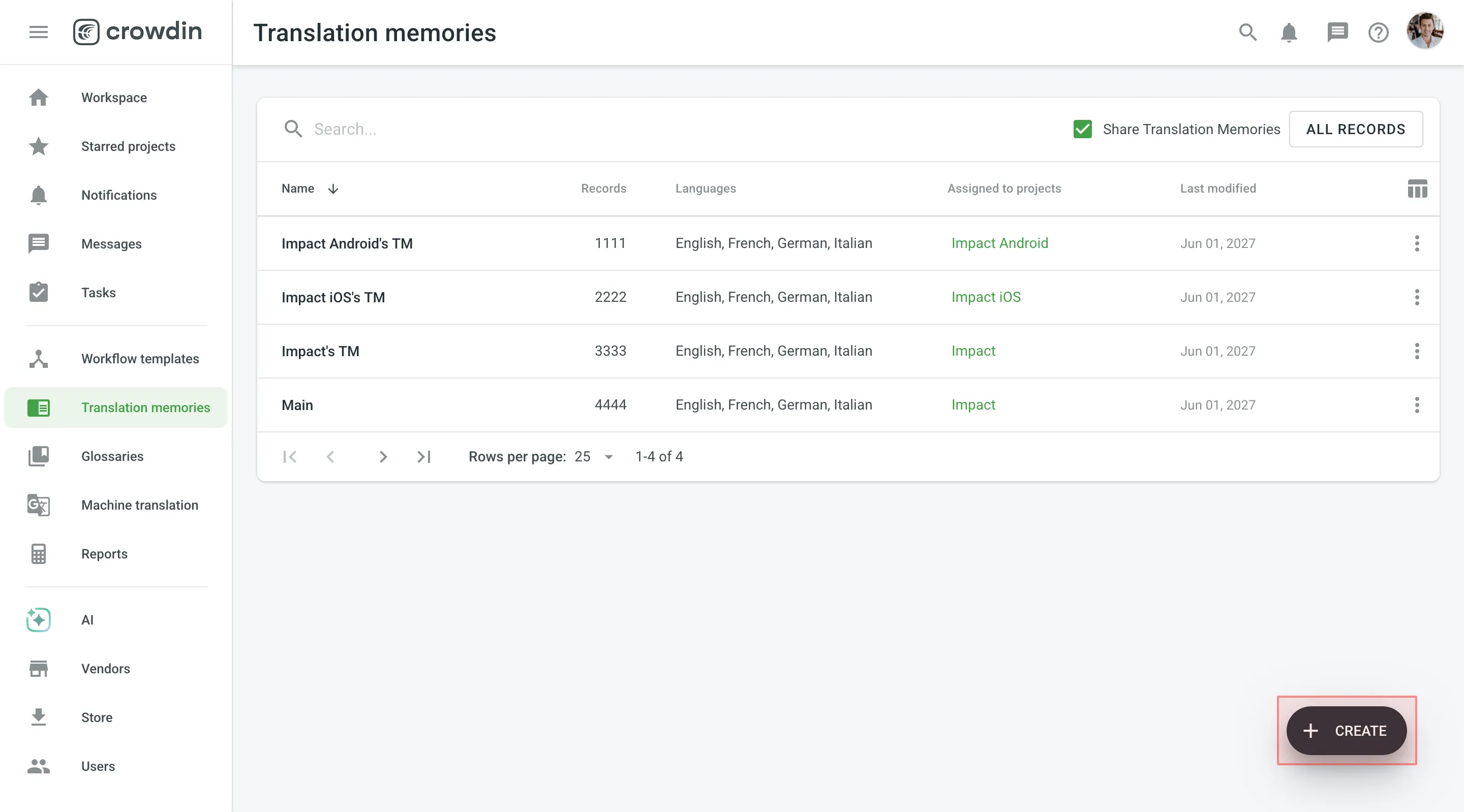
- In the appeared dialog, name your TM and select a default language that will be displayed first in the table of translation units.
- (Optional) Click Select files to upload your existing TM. You can skip this step and upload a TM later.
- Click Create.
You can create translation units from scratch, edit and delete existing translation units or segments of a particular TM or all available TMs.
To create a translation unit, follow these steps:
- Open your organization’s Workspace and select Translation memories on the left sidebar. Alternatively, open your project and go to Settings > Translation memories.
- Select the needed TM and click View Records.
- Click Add Translation Unit.
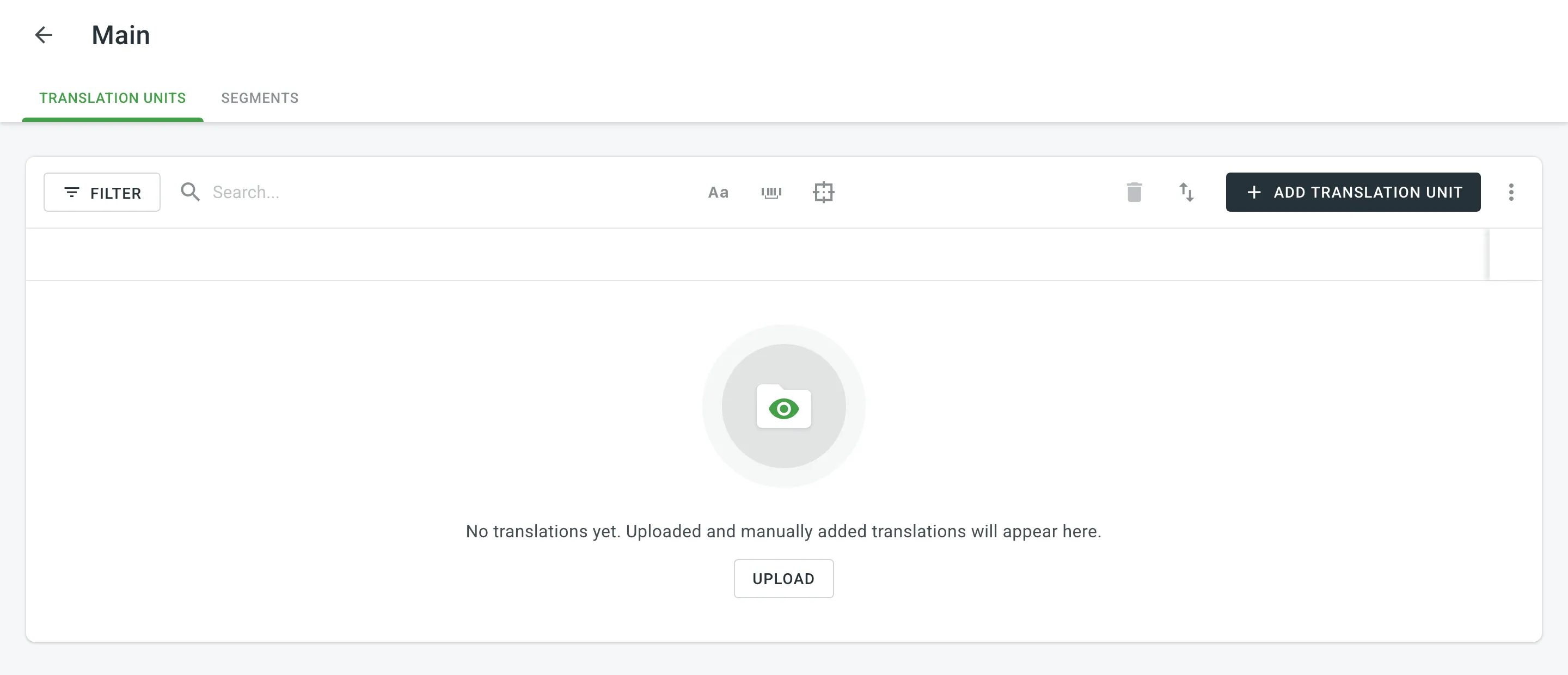
- In the appeared dialog, select the language from the drop-down menu and type the translation of the segment.
- Click Add segment to add more translations for the translation unit.
- Click Save.
Viewing and Filtering Translation Units and Segments
Section titled “Viewing and Filtering Translation Units and Segments”Once you open a translation memory, you can view and filter its translation units and segments using either the Translation Units or Segments pages.
On the Translation Units page, you can view TM content grouped as translation units (one translation unit per row, each segment displayed in a separate language column).
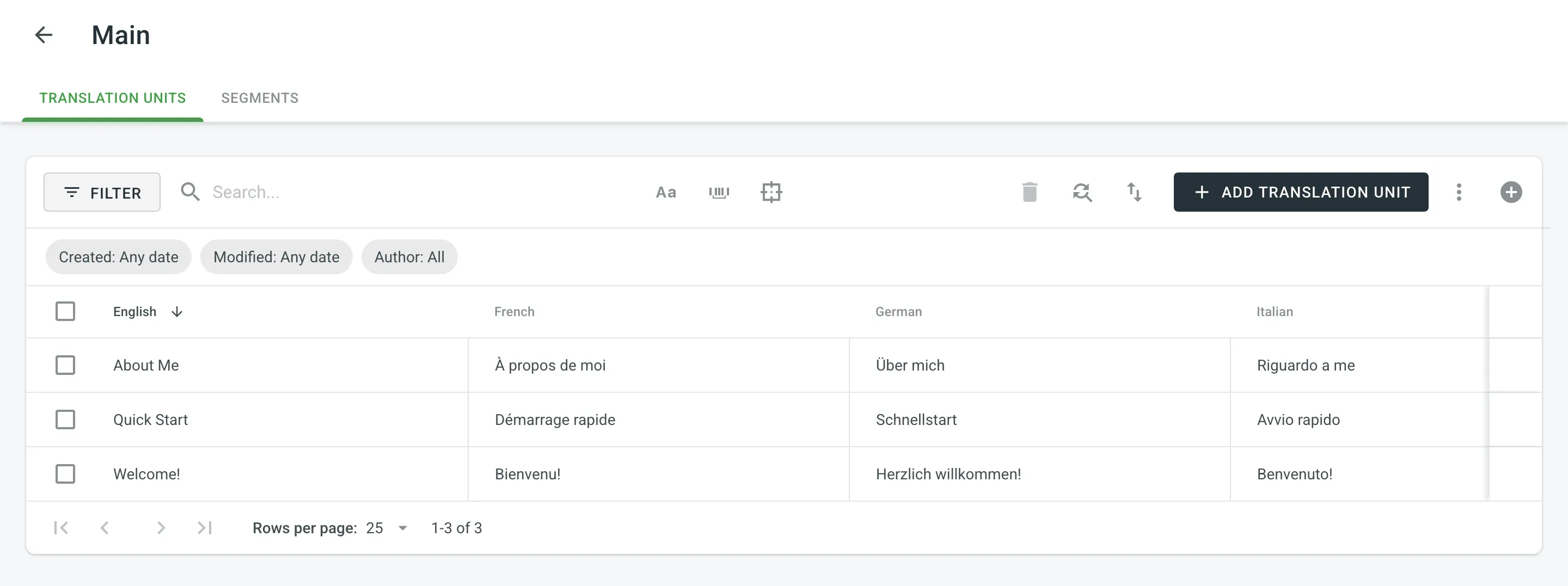
On the Segments page, you can view TM content as individual segments (one segment per row) with the following details:
- Segment – Contains either source or target language text.
- Language – The segment’s language (e.g., French, Spanish).
- Usage count – Specifies the number of times a segment has been used.
- Created – The date the segment was first added to the TM.
- Last modified – The most recent date the segment was edited.
- Author – The user who added the segment to the TM.
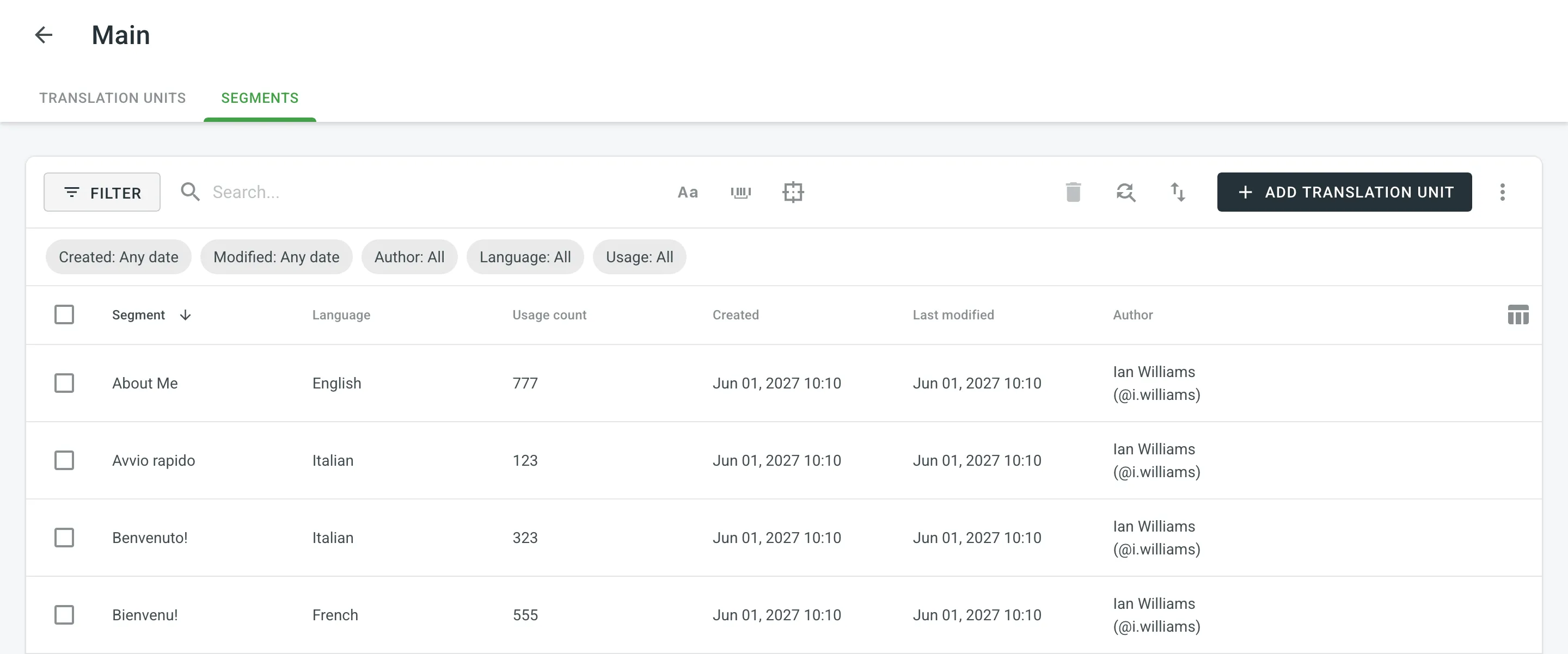
By default, all translation units and segments are displayed in the Translation Units and Segments pages. To filter the translation units or segments displayed, click and use the available filter options:
- Created: All, Custom Range.
- Modified: All, Custom Range.
- Author: All, particular user.
- Languages (Specific to the Segments page): All, particular language.
- Usage (Specific to the Segments page): All, Used, Unused.
To sort translation units or segments, click the column header you want to sort by:
- Translation Units page – click a language column (e.g., English, French, etc.) to sort the translation units by that language’s text.
- Segments page – click the Segment column to sort by segment text.
Click once to sort in ascending order and click again to sort in descending order.
You can edit both the source and translation parts of the existing translation unit.
To edit a translation unit, follow these steps:
- Open your organization’s Workspace and select Translation memories on the left sidebar. Alternatively, open your project and go to Settings > Translation memories.
- Click on the needed TM. Alternatively, click All Records to view translation units of all available TMs in one list.
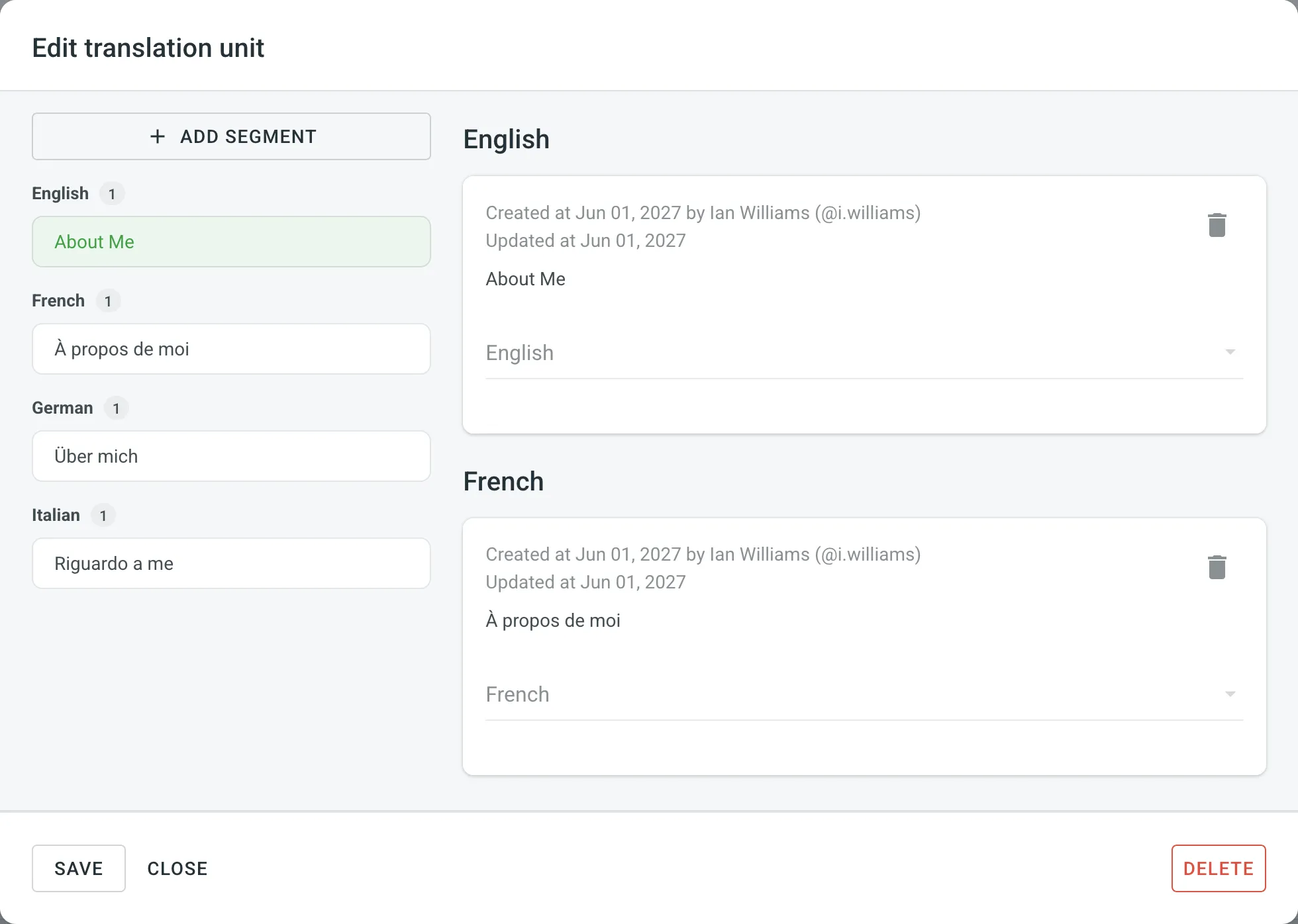
- Hover over a translation unit and click to open it.
- In the appeared dialog, edit or delete the segments of the needed languages. For each segment, you can see additional details like the language, creation date, update date, and, if available, the name of the contributor who originally submitted the translation.
- Click Save.
In addition to editing translation units via the Translation memories page, you can also do it in the Editor.
Read more about Editing TM Suggestions in the Editor.
Another way to edit translation units in your TM is to download it (e.g., in TMX format), make the necessary changes locally on your device, and then reupload the modified TM back to Crowdin.
Depending on what you modify in your TM, there could be different outcomes:
-
If you edit both the source and translation segments of a translation unit, then when you upload the TM to Crowdin, the locally modified translation unit will be treated as new upon re-upload, leaving the original translation unit unchanged.
-
If you only edit the translation segment of a translation unit, then when you upload the TM to Crowdin, the locally modified translation segment will be added as an alternative version segment to the existing translation unit, keeping the original translation intact but providing another option.
If you want to have only the modified version of the translation units, follow these steps:
- Download the complete version of your TM to your device.
- Make the necessary changes locally on your device.
- Completely clear the content of your TM in Crowdin.
- Upload your locally modified TM to Crowdin.
You can easily find and replace translations in segments within a selected TM using the Find & Replace feature.
To replace current translations with the new ones, follow these steps:
- Open your organization’s Workspace and select Translation memories on the left sidebar. Alternatively, open your project and go to Settings > Translation memories.
- Click on the needed TM.
- Click .
- In the appeared dialog, select the language in which you want to search. (Optional) Use filters if necessary.
- Enter the word, phrase, or sentence you want to substitute and the text to replace it with. (Optional) Use the Match case and Exact match options to refine the search results.
- Click Find to preview the segments that will be replaced.
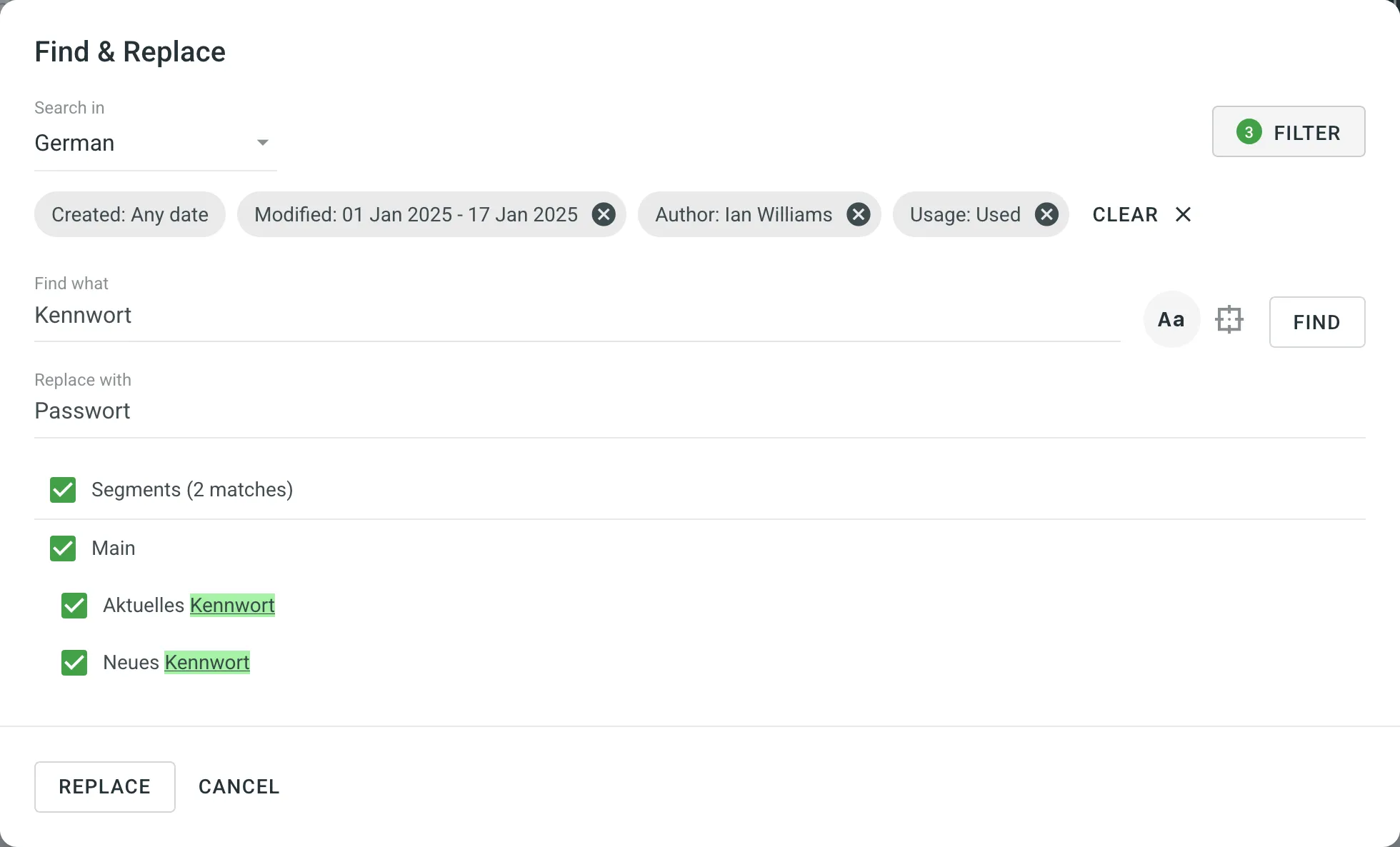
- Select the segments you want to replace and click Replace Selected to finish.
You can delete one, multiple, or all the translation units or segments at once.
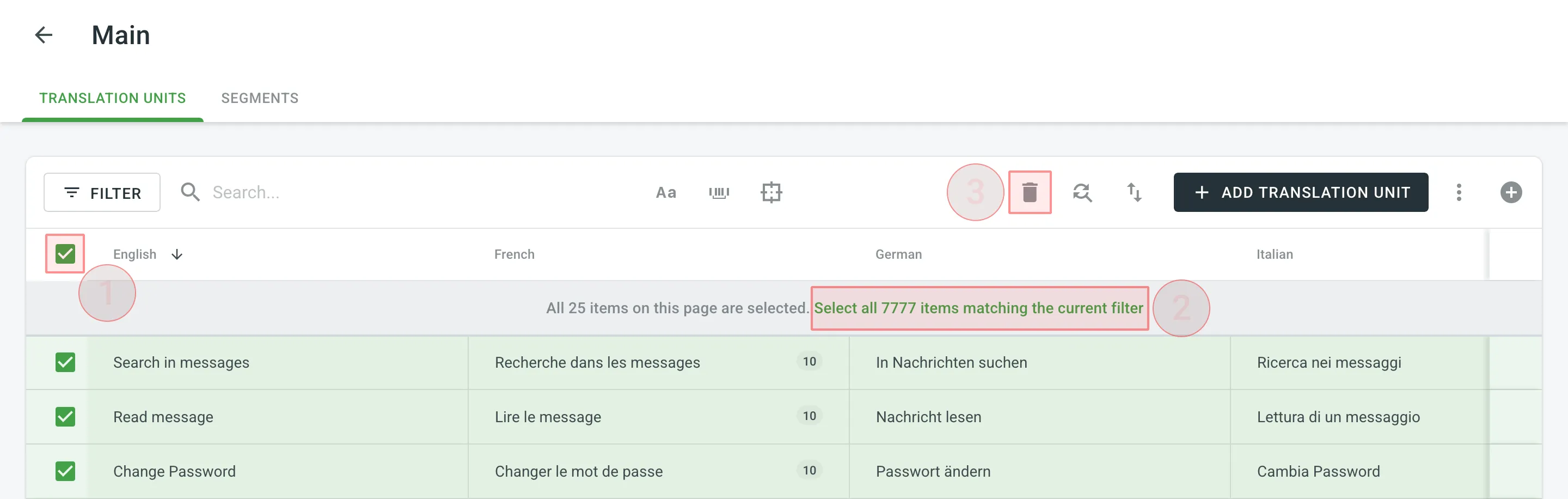
To delete all the translation units from TM, follow these steps:
- On the Translation Units page, select the top checkbox above the translation unit list.
- Confirm the selection of all translation units.
- Click .
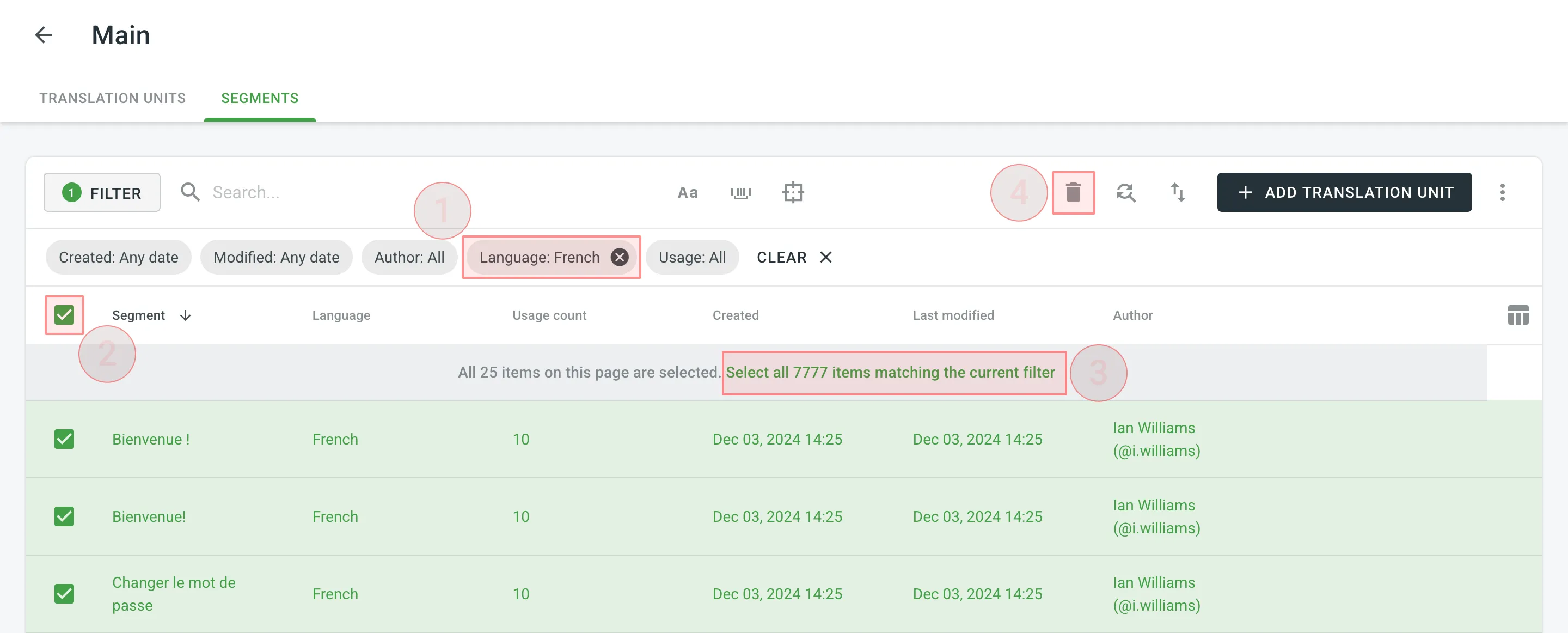
To delete all the segments from TM for only one particular language, follow these steps:
- On the Segments page, click and select the needed language.
- Select the top checkbox above the segment list.
- Confirm the selection of all segments.
- Click .
When dealing with the removal of translation units and translations, there could be three possible outcomes:
- When deleting a translation unit from TM, the related translation won’t be deleted for a string in your Crowdin Enterprise project.
- When you cancel the translation activity for a string on the Activity page, the translation for a string will be deleted, but the related translation unit will be preserved in TM.
- When deleting a translation for a string in the Editor, both the translation and the related translation unit will be deleted.
To download or upload TMs, follow these steps:
- Open your organization’s Workspace and select Translation memories on the left sidebar. Alternatively, open your project and go to Settings > Translation memories.
- Click on the needed TM.
- Click and select Download or Upload.
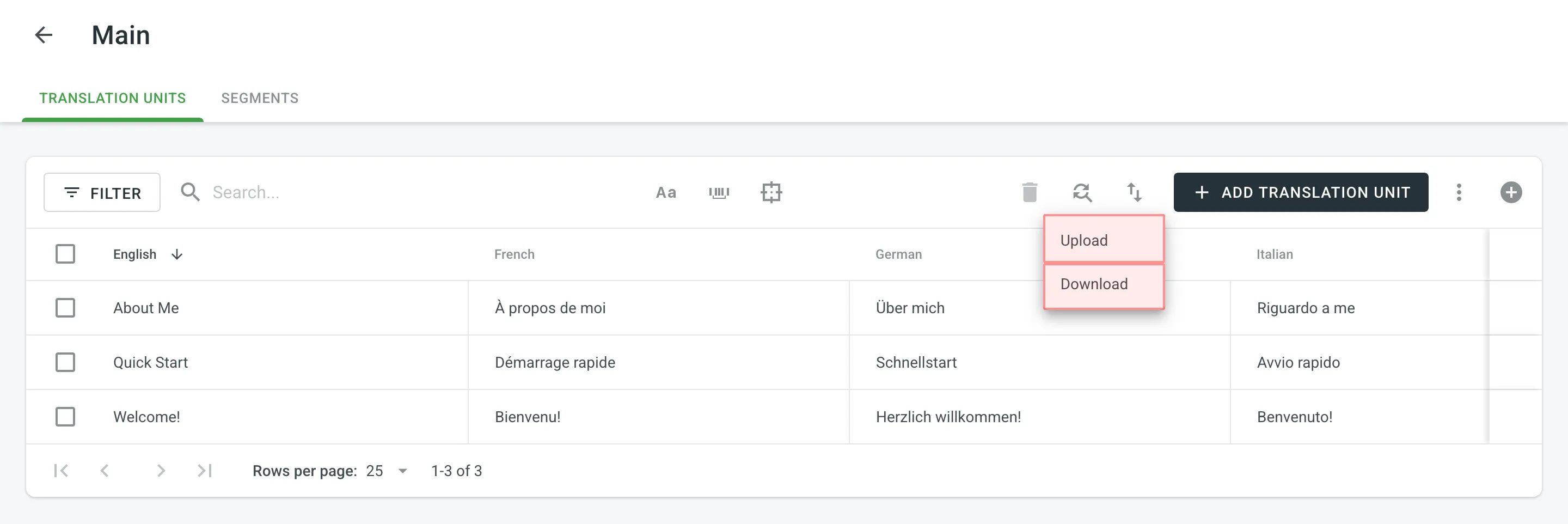
The owner, admins and managers can download and upload TM in the following file formats: TMX, XLSX, or CSV.
If you upload a TM in CSV or XLS/XLSX file formats, match columns with the corresponding languages in the configuration dialog.
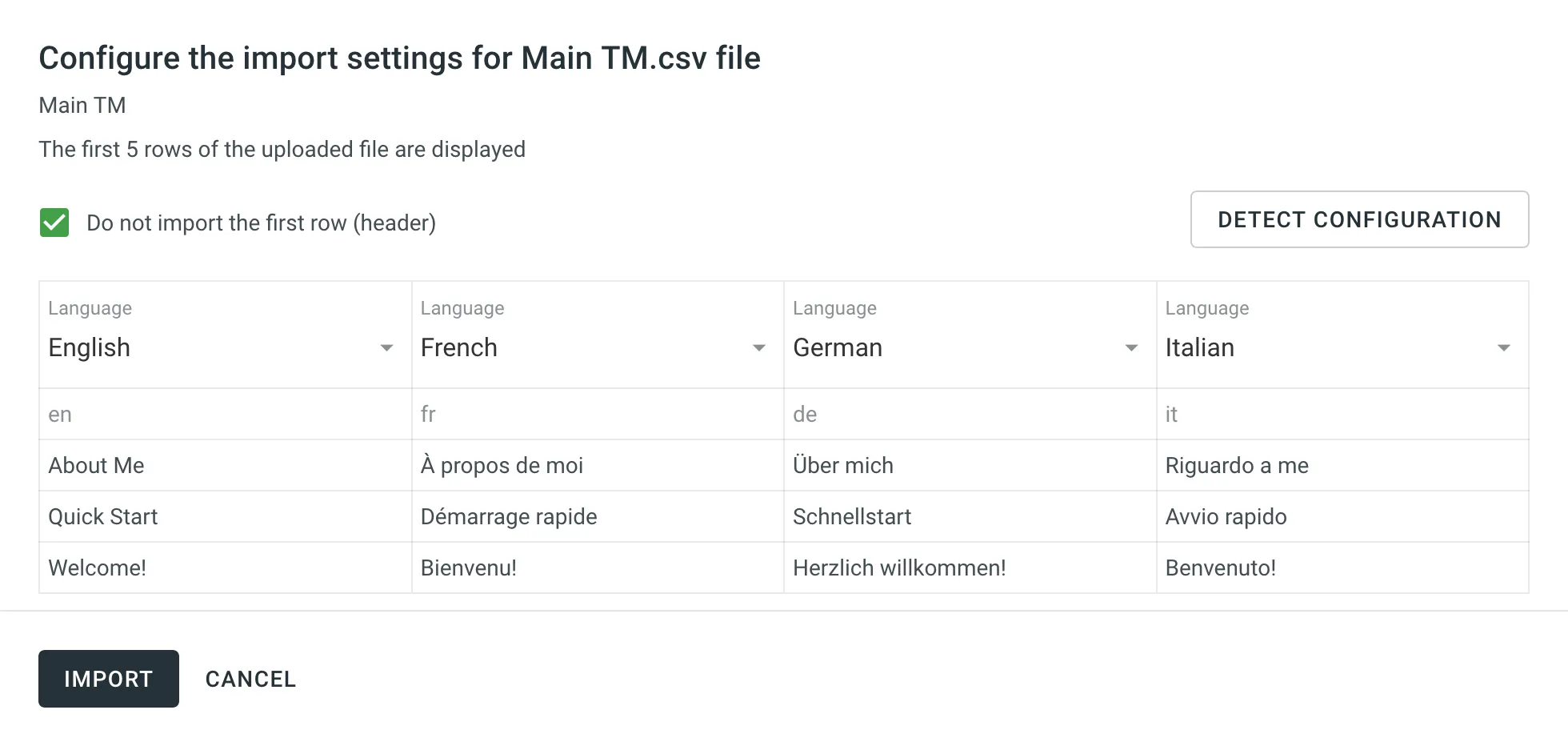
Automatic Column Identification for TM in CSV and XLSX File Formats
Section titled “Automatic Column Identification for TM in CSV and XLSX File Formats”Once you upload your TM file in CSV or XLSX formats, the system automatically detects the file scheme based on the column names specified in the first row. The identification is performed in a case-insensitive manner. Columns that weren’t detected automatically will be left as Not chosen for manual configuration. Automatic column identification is especially helpful when you upload TM spreadsheets that contain many languages.
To get the most out of the automatic column detection, we recommend that you name the language columns in your CSV or XLSX TM files using the values displayed below:
- Language name (e.g., Ukrainian)
- Crowdin language code (e.g., uk)
- Locale (e.g., uk-UA)
- Locale with underscore (e.g., uk_UA)
- Language code ISO 639-1 (e.g., uk)
- Language code ISO 639-2/T (e.g., ukr)
To redetect the TM file scheme, click Detect Configuration.
When downloading a TM from Crowdin Enterprise in TMX format, you can get some additional metadata that might be useful for different usage scenarios with offline tools.
Additional TM attributes provided by translation memory downloaded in TMX format:
x-crowdin-metadata– String identifier hash.creationid– Translation author’s full name and username in Crowdin Enterprise.creationdate– The date the translation was originally created.changeid– Full name and username of the person who updated a translation.changedate– The date the translation was last updated.usagecount– Translation suggestion’s number of usages in Crowdin Enterprise.lastusagedate– The last date a translation suggestion was used in Crowdin Enterprise.
Often translation vendors that work in Crowdin Enterprise export TMs from projects to manage them for their clients in various desktop applications (e.g., for cleaning TMs from irrelevant translations and further reimport back to Crowdin Enterprise). The TM attributes listed above allow better navigation and filtering of TM segments based on different criteria. Also, you might use cleaned and refreshed TMs to train MT engines only on product-specific data to ensure a higher quality of translations as a result.
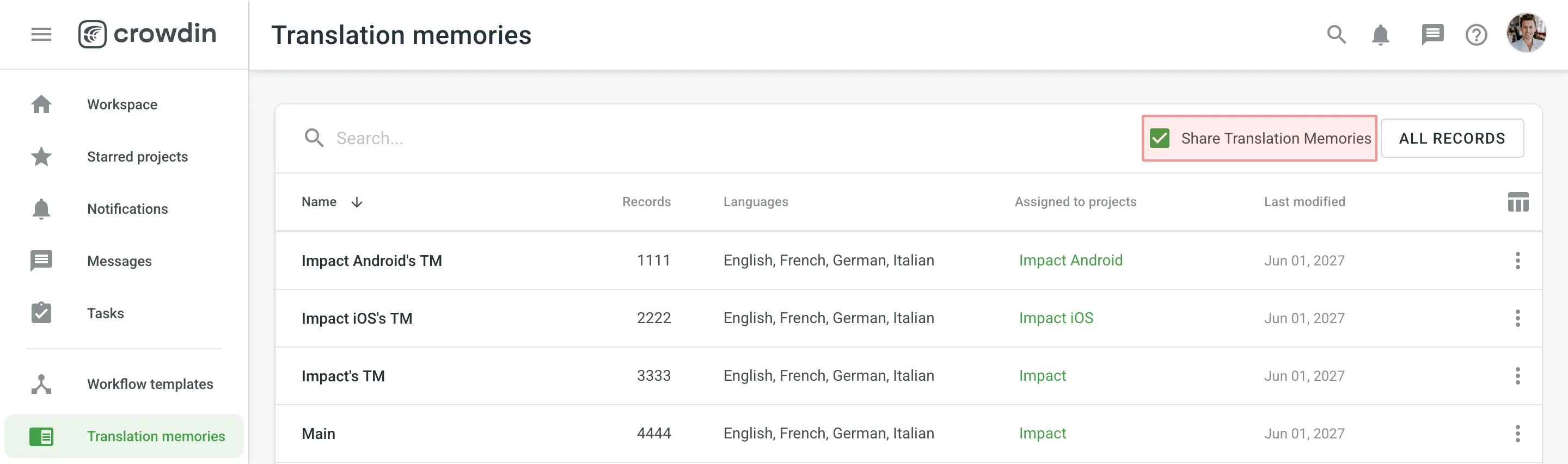
Using the shared TMs, you can auto-translate any of the projects in your organization. Also, TM suggestions from all TMs will appear in the Editor.
To share TMs between all of the projects in your organization, follow these steps:
- Open your organization’s Workspace and select Translation memories on the left sidebar.
- Select Share Translation Memories.
Applying Translation Memory via Auto-translation
Section titled “Applying Translation Memory via Auto-translation”Auto-translation via TM allows you to leverage a configurable (40% to 100% match ratio) and Perfect matches.
Prioritizing TM Suggestions during the Auto-translation via TM
Section titled “Prioritizing TM Suggestions during the Auto-translation via TM”During the auto-translation via TM, the system considers multiple parameters to select the most relevant TM suggestion. If the system finds only one suitable TM suggestion for a string, it will be applied during the auto-translation via TM. If the system finds two or more TM suggestions for one string, they will be sorted based on multiple parameters and applies the most suitable one.
The following parameters are listed in the order the system uses them to decide which TM suggestion works better. If the decision can’t be made using the first parameter (i.e., two TM suggestions with 100% match), the system will use the next parameter until the decision is made.
- Relevance – also known as TM match. Read more about TM Match Calculation.
- Auto-Substitution usage – verifying whether the TM suggestion was improved by the auto-substitution. Read more about Auto-substitution.
- Assigned TM Priority – the priority of the TM a TM suggestion is stored in. Read more about Prioritizing TM.
- Primary or dialect language – the primary or dialect language usage in TM suggestion’s source text (e.g., a TM suggestion from English will have a higher priority than English, Canada).
- TM suggestion creation date – the date a TM suggestion was created (a TM suggestion with a more recent creation date will have a higher priority).
To better understand how TM suggestions are prioritized during the auto-translation via TM, let’s go through a few hypothetical scenarios. Let’s imagine you have an untranslated string in your project with the following source text Welcome!. Once you run the auto-translation via TM, the system starts to search for TM suggestions in your TMs.
- The system finds two TM suggestions with the source text
WelcomeandWelcome!. The translation from theWelcome!TM suggestion will be used since it has a higher TM match. - The system finds two TM suggestions:
Welcome!andWelcome!. Both have the same source text, so the system checks whether the auto-substitution was used to improve these TM suggestions and picks the one that wasn’t improved by the auto-substitution. - The system finds two TM suggestions:
Welcome!andWelcome!. Both have the same source text, and both weren’t improved by the auto-substitution. Then the system checks the priority of the TMs these TM suggestions are stored in and picks the one stored in the TM with higher priority. - The system finds two TM suggestions:
Welcome!andWelcome!. Both have the same source text, both weren’t improved by the auto-substitution, and both are stored in the TMs with the same priority. Then the system checks the source languages of the TM suggestions and picks the one that uses the primary language. - The system finds two TM suggestions:
Welcome!andWelcome!. Both have the same source text, both weren’t improved by the auto-substitution, both are stored in the TMs with the same priority, and both use primary source languages. Then the system checks the TM suggestion creation date and picks the one with the latest date.
In rarer cases, there could be a situation when two or more TM suggestions are identical based on all the parameters listed above. In this case, the system picks the first one among identical.
To improve accuracy, Crowdin minimizes the influence of HTML tags when determining TM matches. Instead of matching based on the original strings, the matching is conducted on strings where HTML tags are replaced with placeholders, similar to the behavior in the Editor.
For example, a string Hello <b>world</b>! will match 100% with a string Hello <a href='#'>world</a>!.
TM Suggestions for Dialect Languages in the Editor
Section titled “TM Suggestions for Dialect Languages in the Editor”When the TM Suggestions for Dialects option is enabled, Crowdin will show TM suggestions from the primary language for dialect languages in the Editor. For instance, if you have Spanish and Spanish, Argentina as your target languages, and the option is enabled, the Editor will display TM suggestions from Spanish for Spanish, Argentina (indicated as “English -> Spanish” in the Automated Suggestions section).
However, this behavior does not apply to the Search TM functionality. If you search for TM suggestions from the primary language in the Search TM tab while working with a dialect language, you will not find any results.
Crowdin Enterprise calculates the TM match by comparing the source string to be translated and TM’s existing segments.
There are three main types of TM matches:
- Perfect Match - TM segment’s text and context completely match the source string
- 100% Match - TM segment’s text matches the source string, but the context is different
- Fuzzy Match (99% and less) - TM segment’s text is different to a certain extent compared to the source string
If the calculations for Perfect and 100% TM match is relatively straightforward, the fuzzy matches’ calculation may not be so obvious.
There are multiple different factors that affect the calculation of fuzzy matches, for example:
- Word order
- Punctuation
- Formatting tags
- Matches that are longer than the source string
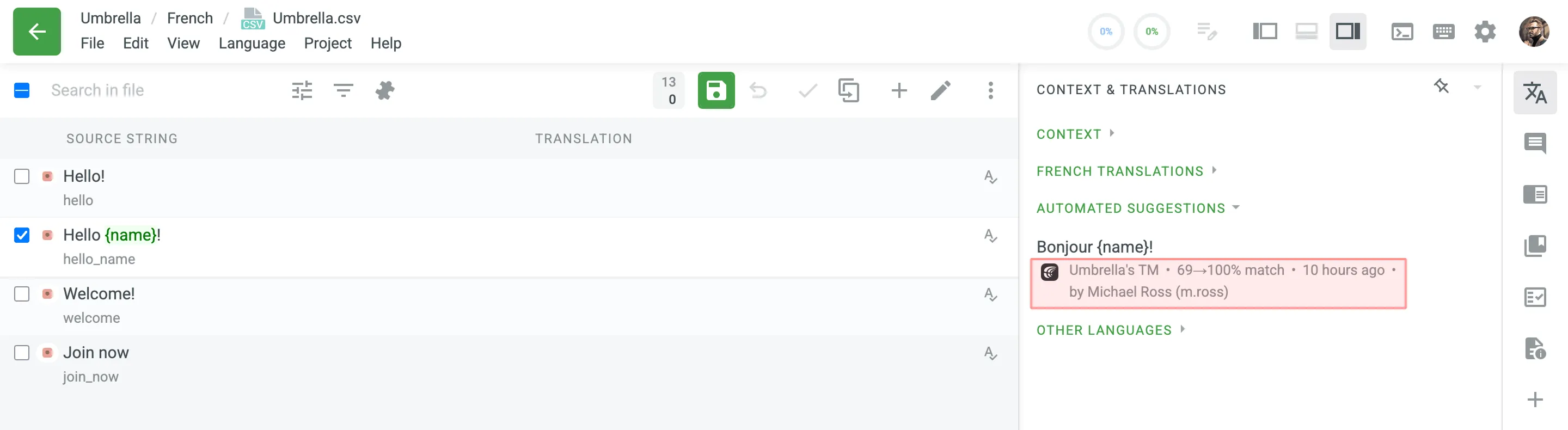
Auto-Substitution is aimed to increase the benefit of using the translation memory (TM) by suggesting translations with a higher similarity match. The feature substitutes the non-translatable elements (such as tags, HTML entities, placeholders, numbers, and more) in translations suggested by TM by the ones used in the source strings.
To enable the Auto-substitution feature, open your project and go to Settings > Translation Memories.
Non-translatable Elements that can be Auto-substituted
Section titled “Non-translatable Elements that can be Auto-substituted”Auto-substitution feature can substitute the following non-translatable elements:
| Non-translatable elements | Source string example | TM suggestion (German) | Improved TM suggestion |
|---|---|---|---|
| Tags | <b %s>Help</b> | <span>Hilfe<span> | <b %s>Hilfe</b> |
| HTML entities | Currency € | Währung ¥ | Währung € |
| Line breaks | Profile | Profil<br/> | Profil |
| Escape sequences (\r\n, \r, \n, \t, unicode, hex) | Translation \x42 | Übersetzung \u4242 | Übersetzung \x42 |
| Non-escaped equivalents of \r\n, \r, \n, \t | Translated by \n TM | Übersetzt vom Übersetzungsspeicher | Übersetzt vom \n Übersetzungsspeicher |
| Placeholders | Example %s | Beispiel %1$s | Beispiel %s |
| Numbers | Attempt 2 | Versuch 5 | Versuch 2 |
| Letter case | Log in | einloggen | Einloggen |
| Special characters | Help? | Hilfe! | Hilfe? |
| URLs | More Information: https://crowdin.com/features | Weitere Infos: https://crowdin.com/ | Weitere Infos: https://crowdin.com/features |
| ICU syntax | Get {discountPercent, number, percent} discount | Erhalte {discountValue, number, currency} Rabatt | Erhalte {discountPercent, number, percent} Rabatt |
Once you enable the TM auto-substitution, you can leverage improved TM suggestions during auto-translation. Be sure to set a minimum match ratio to 100%. This will result in including 100% TM matches along with the ones improved to 100% by TM auto-substitution.
With the Auto-substitution feature, translators can see the improved TM suggestions in the Editor. The percentage below the improved suggestion shows the match percentage of the original TM suggestion and the improved one.
In some cases, you may want to apply penalties to TM suggestions to reduce their match percentage based on specific conditions.
For example, you can set up a penalty for TM suggestions improved by the auto-substitution feature to prioritize exact matches over improved ones. The percentage below the improved and penalized suggestion shows the match percentage of the improved TM suggestion and the penalized one. Hover the cursor over the percentage to see more details.
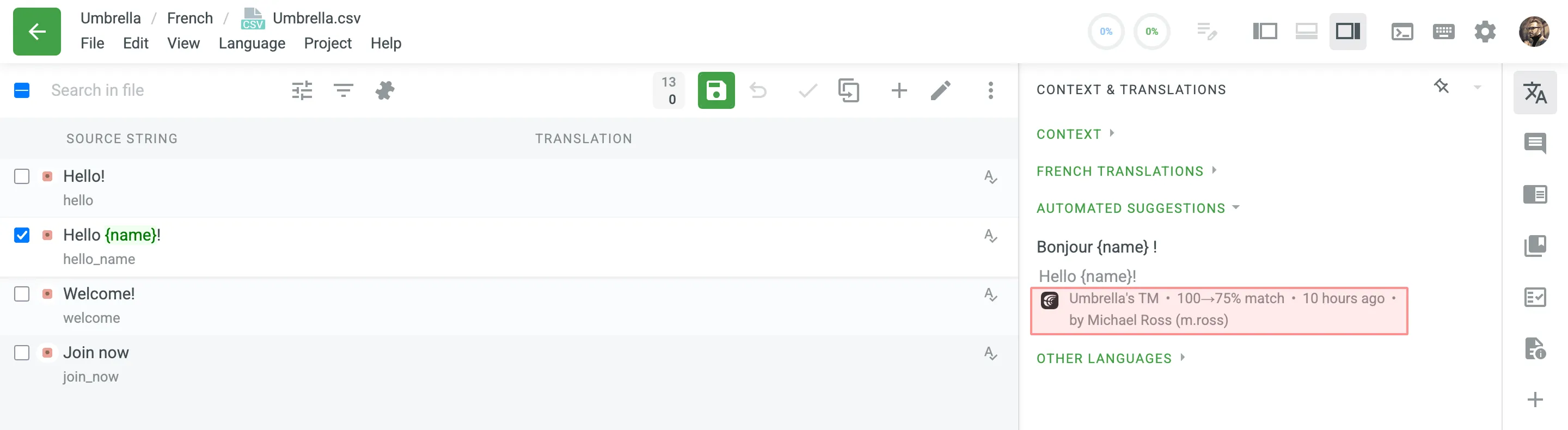
Read more about TM Suggestion Penalties.
Once the feature is enabled, it will affect how the Costs Estimate and Translation Cost reports are calculated.
Costs Estimate report would count TM suggestions that can potentially be improved by the auto-substitution feature based on the highest similarity match to which those strings can be improved. For example, a match that can be improved from a 75% match to a 100% match would be considered a 100% match.
Translation Cost report would count TM suggestions improved by the auto-substitution feature as regular TM suggestions. For example, a match improved from a 75% match to a 100% match would be considered a 100% match.