AI Fine-tuning
Fine-tuning in Crowdin Enterprise enhances AI models using your project-specific data, tailoring translations to your style, tone, and terminology. By leveraging approved translations from your projects and translation memories (TMs), fine-tuning improves translation quality, reduces operational costs, and adapts AI performance to your localization workflows.
Fine-tuning is available for Pre-translate prompts that use supported AI models and providers with custom API credentials, enabling the creation of AI models tailored to your localization needs.
Fine-tuning enhances the performance of AI models, offering the following advantages:
- Improved Accuracy – Models trained on your data align closely with your style, tone, and domain-specific terminology.
- Better Context Handling – Handle edge cases and complex scenarios by training the model with real-world examples from your projects.
- Cost Savings – Fine-tuning reduces token usage by enabling shorter and more precise prompts.
- Incremental Updates – Train models on new data without starting from scratch, saving time and resources.
You can create new fine-tuning jobs, monitor their progress, and review detailed metrics for completed jobs.
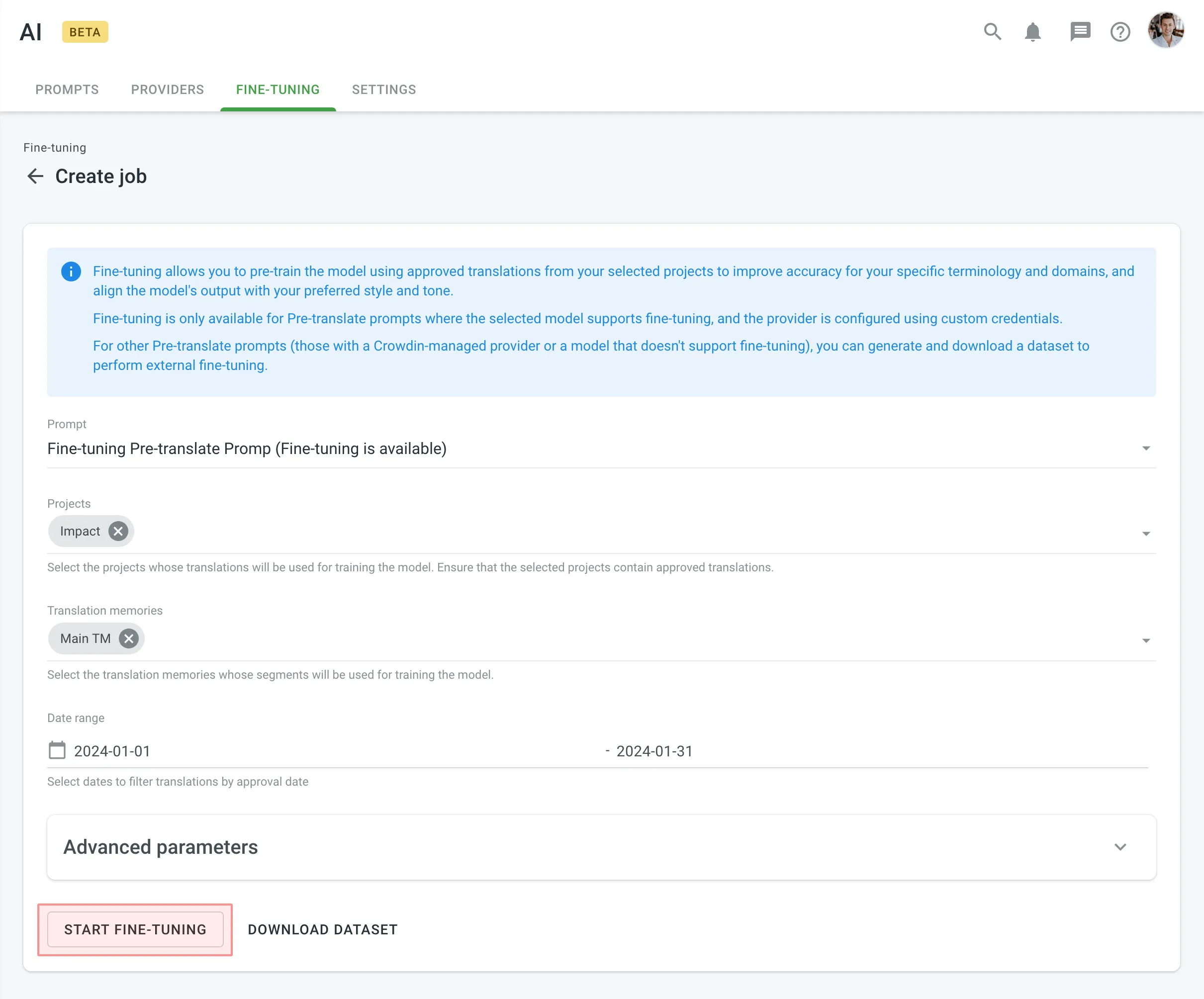
To create a fine-tuning job, follow these steps:
- Open your organization’s Workspace and select AI on the left sidebar.
- In the Fine-tuning tab, click Create to set up a new fine-tuning job.
- Configure the basic parameters and optional advanced parameters. Advanced parameters are typically adjusted for complex datasets or when fine-tuning a model for specific domain requirements.
- (Optional) Estimate the fine-tuning cost before proceeding.
- Click Start fine-tuning.
- Monitor the fine-tuning progress in the Fine-tuning Jobs section and evaluate results after completion.
Estimating the cost of fine-tuning before running the process helps you ensure that the training fits within your budget and allows you to adjust parameters for optimal results. This step is particularly useful if you’re working with a large dataset or running multiple fine-tuning jobs.
To estimate the cost of fine-tuning, follow these steps:
- Go to Advanced Parameters and set the Epochs Number to 1.
- Click Start fine-tuning.
- The system will calculate and display the approximate fine-tuning price. At this point, you can:
- Click Proceed to start the actual fine-tuning if the price aligns with your expectations.
- Click Back to adjust the parameters and refine your configuration to potentially lower the cost.
By estimating costs upfront, you avoid unnecessary expenses and can experiment with different configurations to strike the right balance between performance and budget.
Once you open the Fine-tuning tab on the AI page, you can view and filter fine-tuning jobs to monitor their progress and results.
You can view a list of all created fine-tuning jobs with the following details:
- Job ID – the unique identifier of the fine-tuning job.
- Status – the current state of the job (e.g., In Progress, Finished, Failed).
- Created At – the date and time the job was created.
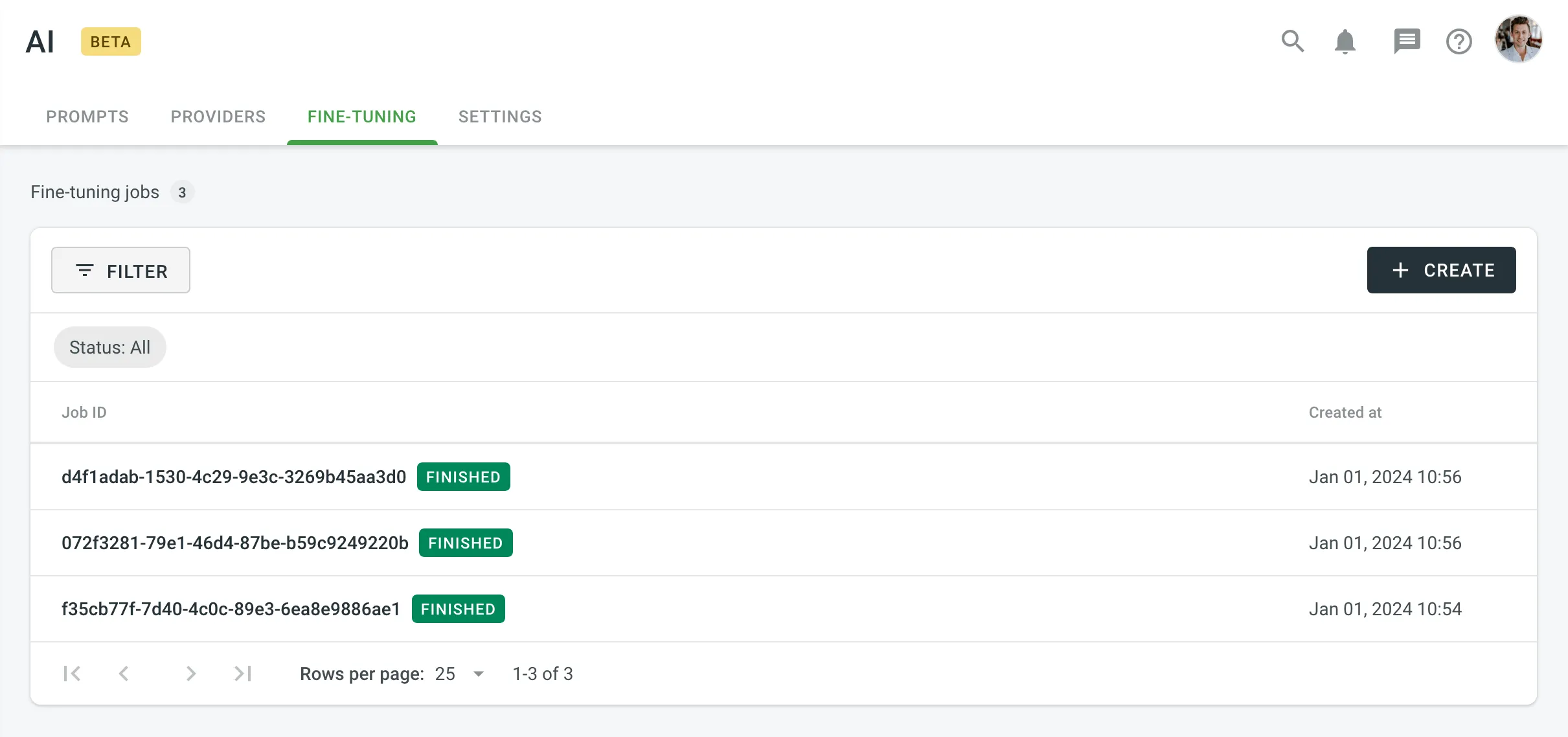
To filter jobs, click and apply the following filters:
- Status: All, Finished, In Progress, Failed.
Click Clear to reset filters and display all jobs.
Clicking on a job opens its detailed metrics, including parameters, results, logs, and other relevant information.
You can configure a fine-tuning job using basic and advanced parameters.
The following parameters are required for initiating fine-tuning:
- Prompt – Choose the Pre-translate prompt to be fine-tuned.
- Projects – Select projects whose translations will be used for training. Ensure the selected projects contain approved translations.
- Translation Memories – Include TM segments for training data. Leave blank to exclude TMs.
- Date Range (Optional) – Specify the approval date range for filtering translations.
Advanced parameters provide greater control over the fine-tuning process and include options for both training and validation datasets.
Training dataset parameters control the data used to train your model. These settings determine the size and scope of the dataset, ensuring it’s sufficient for effective training:
- Batch Size – The number of examples in each batch during training. Larger batch sizes reduce variance but increase training time.
- Learning Rate Multiplier – Adjust the scaling factor for the learning rate. Smaller values help prevent overfitting, while larger values speed up learning.
- Epochs Number – The number of complete passes through the training dataset. Higher values improve accuracy but increase costs.
- Dataset Size Constraints –
- Maximum Dataset File Size (in bytes) – Restricts the size of the training dataset.
- Minimum Number of Examples in Dataset – Sets the lower limit for training data size.
- Maximum Number of Examples in Dataset – Sets the upper limit for training data size.
Validation datasets are used to test how well the fine-tuned model performs on unseen data. Configuring a validation dataset is optional but recommended for assessing model performance.
- Projects – Select different projects from those used for training.
- Translation Memories – Include TM segments for validation.
- Date Range – Filter translations by approval dates for validation.
- Dataset Size Constraints –
- Maximum Dataset File Size (in bytes) – Restricts the size of the validation dataset.
- Minimum Number of Examples in Dataset – Sets the lower limit for validation data size.
- Maximum Number of Examples in Dataset – Sets the upper limit for validation data size.
After fine-tuning is complete, a new model is generated along with detailed metrics, including training and validation losses, job parameters, and logs. Use this data to evaluate your model’s performance and determine if it’s ready to integrate into your Pre-translate prompt.
Key information about your fine-tuned model includes:
- Model: Name of the fine-tuned model.
- Status: Job status (e.g., In progress, Finished, Failed).
- Job ID: Unique identifier for the fine-tuning job.
- Base Model: Initial model used as a starting point for fine-tuning.
- Output Model: Name of the resulting fine-tuned model.
- Created At: Date and time when the job was initiated.
Details about the parameters configured for the fine-tuning job:
- Trained Tokens: Total tokens processed during training.
- Epochs Number: Number of full passes through the dataset.
- Batch Size: Number of examples in each training batch.
- Learning Rate Multiplier: Scaling factor for the learning rate, determining how quickly the model adjusts weights during training.
Dataset files used for fine-tuning, allowing you to download them for further analysis or external processing:
- Training: File containing the training dataset used to train the fine-tuned model.
- Validation: File containing the validation dataset used to evaluate the fine-tuned model’s accuracy and generalization performance.
Metrics and tools available for assessing your fine-tuned model’s performance:
- Training Loss: Indicates how well the model fits the training data. Lower values indicate better learning.
- Validation Loss: Assesses who well the model performs on unseen data. Available only if a validation dataset is configured.
- Full Validation Loss: Represents the model’s overall performance on the entire validation dataset, if applicable.
Review the results to determine whether they meet your requirements. If so, you can integrate the fine-tuned model into your Pre-translate prompt for immediate use.
Crowdin Enterprise provides multiple ways to evaluate fine-tuning results, including interactive graphs and a detailed metrics table.
- Interactive Graphs – Visualize fine-tuning metrics such as Training Loss, Validation Loss, and Full Validation Loss over the course of training. Hover over points on the graph for step-specific details. You can highlight or hide specific metrics by clicking their titles below the graph.
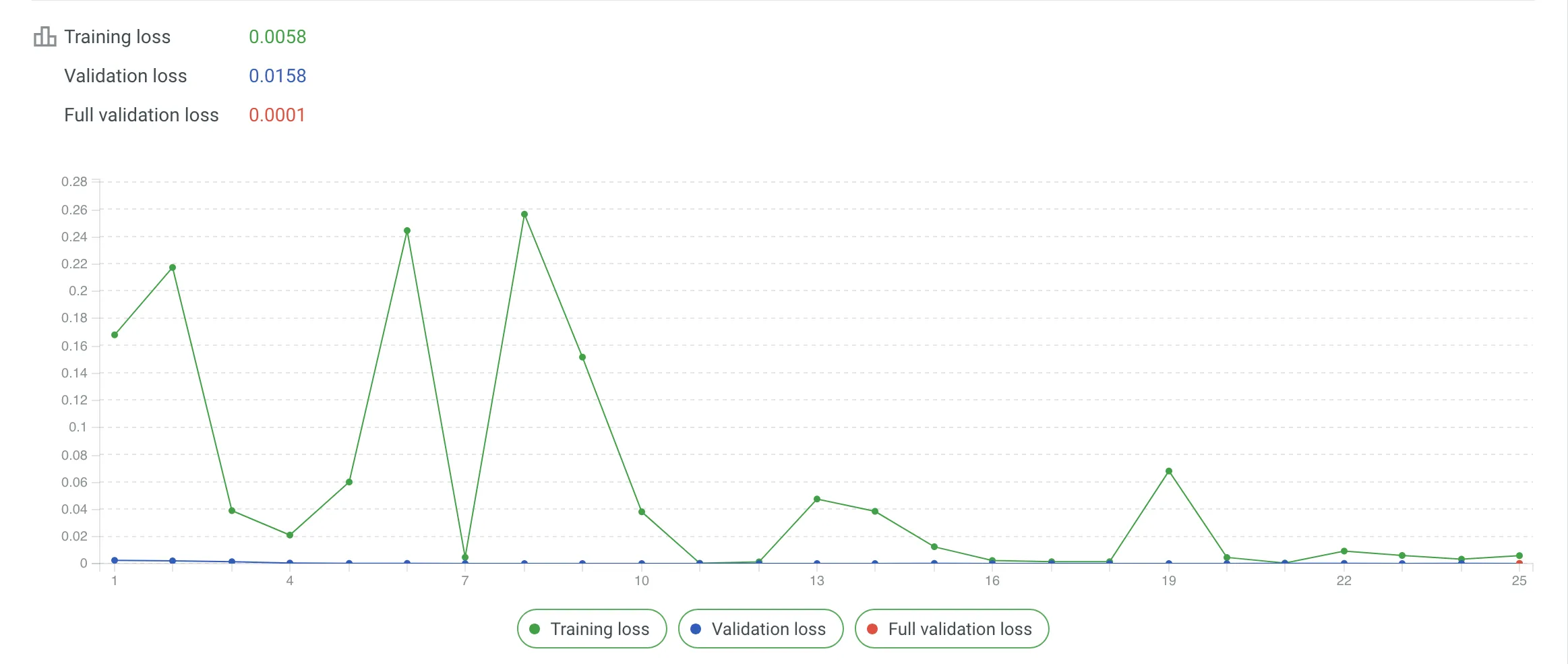
- Metrics Tab – Access the same data in table format for a comprehensive overview. The table provides a step-by-step breakdown, making it easier to identify patterns or issues during fine-tuning. A steady decline in loss values across steps reflects effective training, with values closer to zero indicating better results.
Both tools are available in the Fine-tuning Job Details page, allowing you to analyze performance trends and troubleshoot any anomalies effectively.
The Messages tab provides logs returned by the AI provider, offering a detailed timeline of the job’s progress, including key milestones (e.g., checkpoint creation, job completion) and troubleshooting insights.
Update fine-tuned models iteratively to include newly approved translations. Use the Date Range parameter to avoid retraining from scratch.
Example workflow:
- Initial Fine-tuning – Train a base model using the full dataset.
- Subsequent Fine-tuning – Train on newly approved translations only to create an updated model while retaining prior training data.
Incremental fine-tuning is ideal for projects with ongoing updates, allowing you to keep your model optimized without retraining from scratch.
Crowdin Enterprise allows you to download datasets for external tools or local validation, or in cases where fine-tuning is not performed within the platform.
Available dataset options:
- Training Dataset – Contains data used for model training, including translations from selected projects and translation memories.
- Validation Dataset – Contains data used to evaluate model accuracy, ensuring the trained model performs well on unseen data.
To download a dataset, follow these steps:
- Open your organization’s Workspace and select AI on the left sidebar.
- In the Fine-tuning tab, click Create.
- Configure the datasets using basic parameters and advanced parameters.
- Click Download dataset and select your preferred dataset type for export.