Custom Segmentation
Each time you upload XML, HTML, MD, or any other source files without a key-value structure, the predefined segmentation rules (SRX 2.0) are used for automatic content segmentation. Although, there might be situations when the default segmentation rules segment source files in contrast to the desired expectations.
In this case, you can define your own segmentation rules for each source file individually using the SRX 2.0 standard.
You can change segmentation in Sources > Files.
- Open the project where you’d like to adjust the segmentation rules and go to Sources > Files.
- Click (or right-click) on the needed file and select Settings.
- In the appeared dialog, switch to the Parser configuration tab.
- In the Excluded elements field, specify all elements that should not be imported.
- Select Enable content segmentation and Use custom segmentation rules.
- Paste your SRX segmentation rules and click Save.
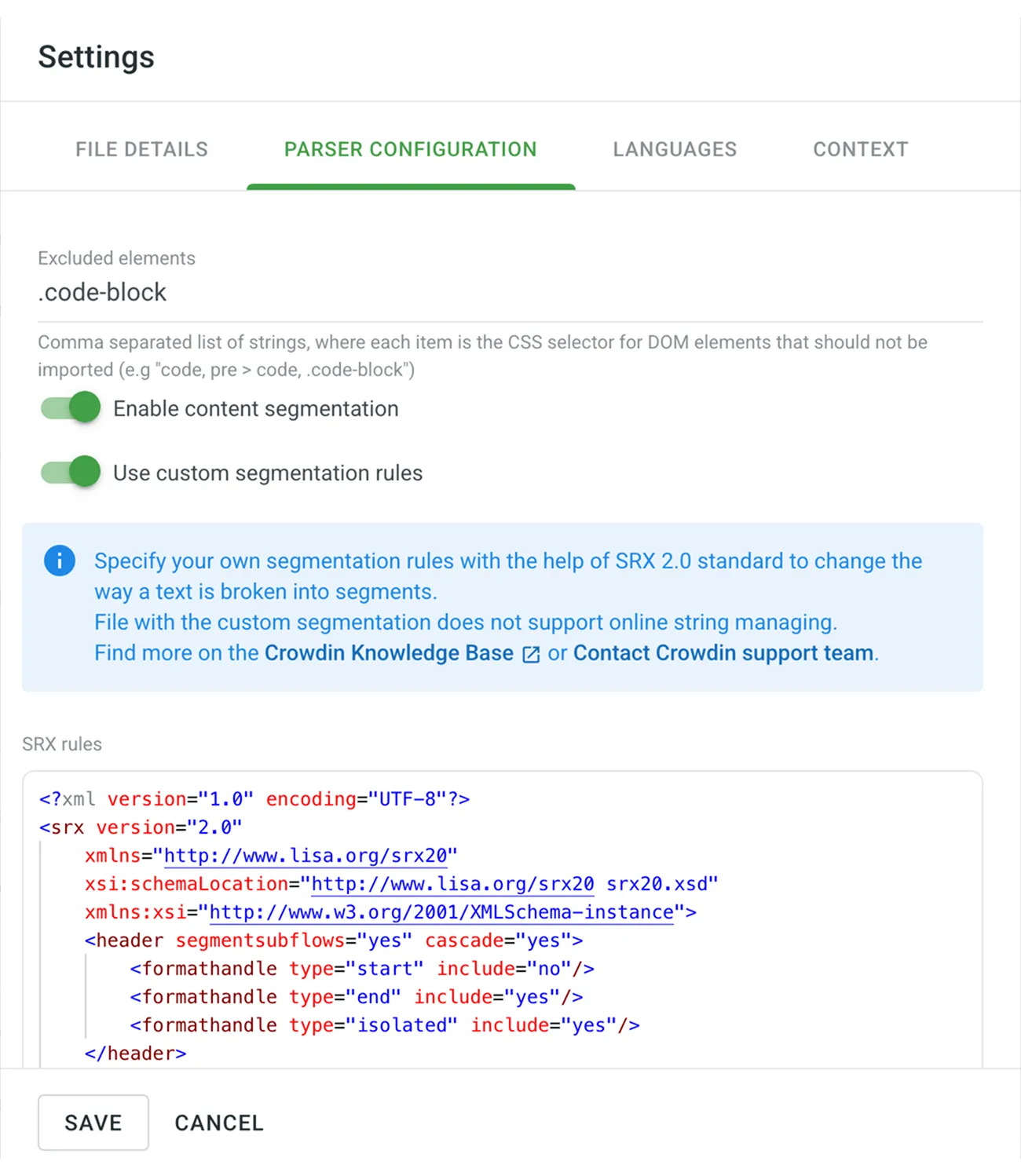
After you save your new segmentation rules, your source file will be automatically reimported and segmented according to these new rules.
A typical SRX file looks similar to the following:
<?xml version="1.0" encoding="UTF-8"?><srx version="2.0" xmlns="http://www.lisa.org/srx20" xsi:schemaLocation="http://www.lisa.org/srx20 srx20.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <header segmentsubflows="yes" cascade="yes"> <formathandle type="start" include="no"/> <formathandle type="end" include="yes"/> <formathandle type="isolated" include="yes"/> </header> <body> <languagerules> <languagerule languagerulename="Default"> <!-- Common rules for most languages --> <rule break="no"> <beforebreak>^\s*[0-9]+\.</beforebreak> <afterbreak>\s</afterbreak> </rule> <rule break="yes"> <afterbreak>\n</afterbreak> </rule> <rule break="yes"> <beforebreak>[\.\?!]+</beforebreak> <afterbreak>\s</afterbreak> </rule> </languagerule> </languagerules> <maprules> <!-- List exceptions first --> <languagemap languagepattern="[Ee][Nn].*" languagerulename="English"/> <languagemap languagepattern="[Ff][Rr].*" languagerulename="French"/> <!-- Japanese breaking rules --> <languagemap languagepattern="[Jj][Aa].*" languagerulename="Japanese"/> <!-- Common breaking rules --> <languagemap languagepattern=".*" languagerulename="Default"/> </maprules> </body></srx>Change Sentence Separator for Asian Languages
Section titled “Change Sentence Separator for Asian Languages”Usually, the full stop is used as a sentence separator. Although, for some Asian languages, it’s not the case. For example, the typical sentence separator in Chinese is an ideographic full stop (。). For such cases, you may want to use the following ruleset:
<rule break="yes"> <beforebreak>[\x3002]+</beforebreak> <afterbreak></afterbreak></rule>In the following simple sentence, we’ll break down a case when segmenting one text piece into two (or more) strings is necessary.
Text with default segmentation rules:
This is the first part of the sample sentence and this is the second part.
Text with new segmentation rules:
This is the first part of the sample sentence
and this is the second part.
For this particular case, the following ruleset will break the initial sentence into two parts:
<rule break="yes"> <beforebreak>sentence</beforebreak> <afterbreak>\u0020</afterbreak></rule>Create Segmentation Rules with SRX Editors
Section titled “Create Segmentation Rules with SRX Editors”The SRX segmentation rules can be created and maintained with the help of tools like Ratel. It has a visual interface where you can generate segmentation rules from scratch or edit your existing ones.