Stringhe Duplicate
Configura le impostazioni per le stringhe duplicati per ottenere la massima efficienza del processo di localizzazione e risparmiare sui costi.
Panoramica
In Crowdin Impresa, il processo di localizzazione è basato sulla traduzione delle stringhe sorgente alle lingue di destinazione definite. In Crowdin Impresa, il processo di localizzazione è basato sulla traduzione delle stringhe sorgente alle lingue di destinazione definite. Ogni stringa d’origine univoca che è stata precedentemente caricata o aggiunta (per i CSV e altri formati che supportano la modifica della stringa) su Crowdin Imprese, è considerata stringa principale. Tutte le altre stringhe sono identiche alla stringa principale ma sono state caricate o create in seguito sono considerate stringhe duplicate.
Gestione delle Stringhe Duplicate
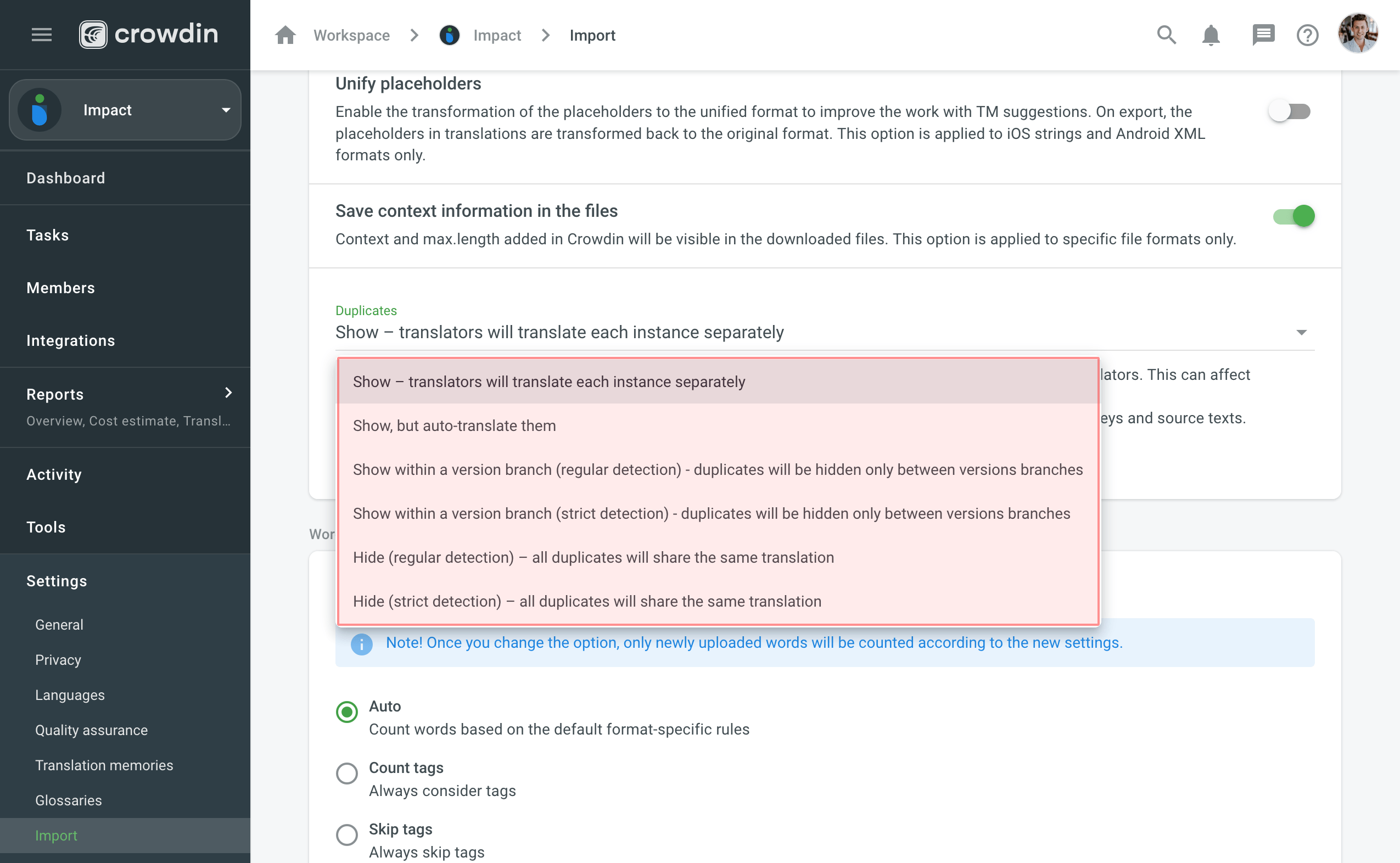
Esistono sei opzioni principali per lavorare con stringhe duplicate in Crowdin Impresa:
- Mostra – i traduttori tradurranno ogni istanza separatamente.
- Mostra, ma traduci automaticamente.
- Mostra entro un ramo della versione (rilevamento regolare) – i duplicati saranno nascosti solo tra i rami della versione.
- Mostra in un ramo di versione (rilevamento rigoroso) – i duplicati saranno nascosti solo tra rami di versione.
- Nascondi (rilevamento regolare) – tutti i duplicati condivideranno la stessa traduzione.
- Nascondi (rilevamento rigoroso) – tutti i duplicati condivideranno la stessa traduzione.
Il rilevamento regolare dei duplicati – comparando le stringhe, Crowdin Impresa considera solo i testi sorgente.
Il rilevamento rigido dei duplicati – comparando le stringhe, Crowdin Impresa considera sia gli identificativi della stringa (chiavi) che i testi sorgente.
Mostra tutti i duplicati
Quando quest’opzione è selezionata, tutte le stringhe duplicate saranno visibili ai traduttori. Quando quest’opzione è selezionata, tutte le stringhe duplicate saranno visibili ai traduttori.
Caso d’uso: funziona perfettamente per i progetti dove le stesse parole potrebbero avere significati diversi in base al contesto.
Mostra, ma traduci automaticamente i duplicati
When this option is selected, all duplicate strings are shown and automatically translated. Once the master string is translated, its translation is automatically shared among all duplicates. This allows translators to review and re-translate duplicate strings if necessary.
Use case: works excellently if you want to save time but still require automatic translations to be reviewed.
To better illustrate how the Show, but auto-translate them option works, consider the following five-string JSON file: two strings are unique, and three strings have identical source text.
{
"hello": "Hello",
"welcome": "Welcome!",
"save1": "Save",
"save2": "Save",
"save3": "Save"
}
Upon importing this file, the system marks the first of these identical strings ("save1": "Save") as the master string with the “Master” marking, while the subsequent two identical strings ("save2": "Save" and "save3": "Save") are labeled as duplicates of this master string with the “Duplicate” marking.
Once you set the Duplicate strings option to Show, but auto-translate them, the system keeps all five strings visible to translators and for the master string and its two duplicates, automatic translation propagation is enabled. This means that translations are automatically shared from the master string to its duplicates.
Let’s consider the following scenarios:
-
Master string is translated first – the system immediately propagates the translation of the master string to its duplicates. As a result, all three identical strings (the master string and its two duplicates) are displayed with translations. However, translators can review and re-translate each duplicate with their own translation as needed. If a unique translation is provided for a specific duplicate, it will override the shared translation for that string alone, allowing for precise context-specific translations without affecting the other duplicates. If a translator removes a duplicate’s unique translation, it will be automatically translated with a translation from a master string.
-
One of the duplicates is translated first – the system does not propagate the translation of the duplicate to the master string or the other duplicate. Consequently, one duplicate string is displayed with a translation, while the master string and the other duplicate remain untranslated.
Mostra entro un ramo della versione. I duplicati sono nascosti solo tra i rami della versione
Quando quest’opzione è selezionata, solo le stringhe principali originariamente caricate al sistema saranno disponibili per le traduzioni. Tutte le stringhe duplicate otterranno automaticamente le traduzioni delle stringhe originali e saranno nascoste in tutti i rami della versione. Quest’opzione è disponibile in due versioni: il rilevamento dei duplicati regolari, il rilevamento dei duplicati rigidi. If your source files contain strings with apparent identifiers (keys), it’s better to use a strict version of this option. In other cases, feel free to use a regular one.
Un paio di cose da tenere a mente:
- Il sistema controlla sempre il percorso alla stringa tramite i rami. Ad esempio, anche se le stringhe sono uguali nei diversi rami di versione (ramo1 e ramo2, ma i loro percorsi sono differenti (ramo1 - /localization/android.xml e ramo2 - /localization/apps/android.xml), non saranno riconosciute come duplicati.
- Quest’opzione funziona solo per le stringhe site nei file aventi lo stesso formato. Ad esempio, se c’è la stessa stringa nei file android.xml e ios.strings, non sarà riconosciuta come duplicato.
Caso d’uso: funziona perfettamente per i progetti continui con vari rami di versione. Consente ai traduttori di operare con stringhe uniche in rami separati.
Nascondi tutti i duplicati
Quando quest’opzione è selezionata, il sistema individua le stringhe duplicate in tutti i file. Solo le stringhe principali originariamente caricate sono visibili e dovrebbero esser tradotte. Le stringhe duplicate e nascoste condivideranno automaticamente le traduzioni dalle stringhe principali corrispondenti. Quest’opzione è disponibile in due versioni: il rilevamento dei duplicati regolari, il rilevamento dei duplicati rigidi. If your source files contain strings with apparent identifiers (keys), it’s better to use a strict version of this option. In other cases, feel free to use a regular one.
Caso d’uso: funziona ottimamente per i progetti con ambiti ristretti dove tutti i duplicati condividono lo stesso contesto.