Segmentação Personalizada
Nesse caso, você pode definir suas próprias regras de segmentação para cada arquivo de origem individualmente usando o Padrão SRX 2.0. No entanto, pode haver situações em que as regras de segmentação padrão segmentam os arquivos de origem em contraste com as expectativas desejadas. Cada vez que você enviar XML, HTML, MD ou qualquer outro arquivo de origem sem uma estrutura de valor-chave, as regras de segmentação predefinidas (SRX 2.0) são usadas para segmentação automática do conteúdo.
Alterar Segmentação
Você pode alterar a segmentação em Fontes > Arquivos.
- Abra o projeto onde deseja ajustar as regras de segmentação e vá para Fontes > Arquivos.
- Clique em
 (ou clique com o botão direito) no arquivo necessário e selecione Configurações.
(ou clique com o botão direito) no arquivo necessário e selecione Configurações. 
- Na caixa de diálogo exibida, mude para a guia Configuração do analisador.
- Selecione Ativar segmentação de conteúdo e Usar regras de segmentação personalizadas.
- Cole suas regras de segmentação SRX e clique em Salvar.
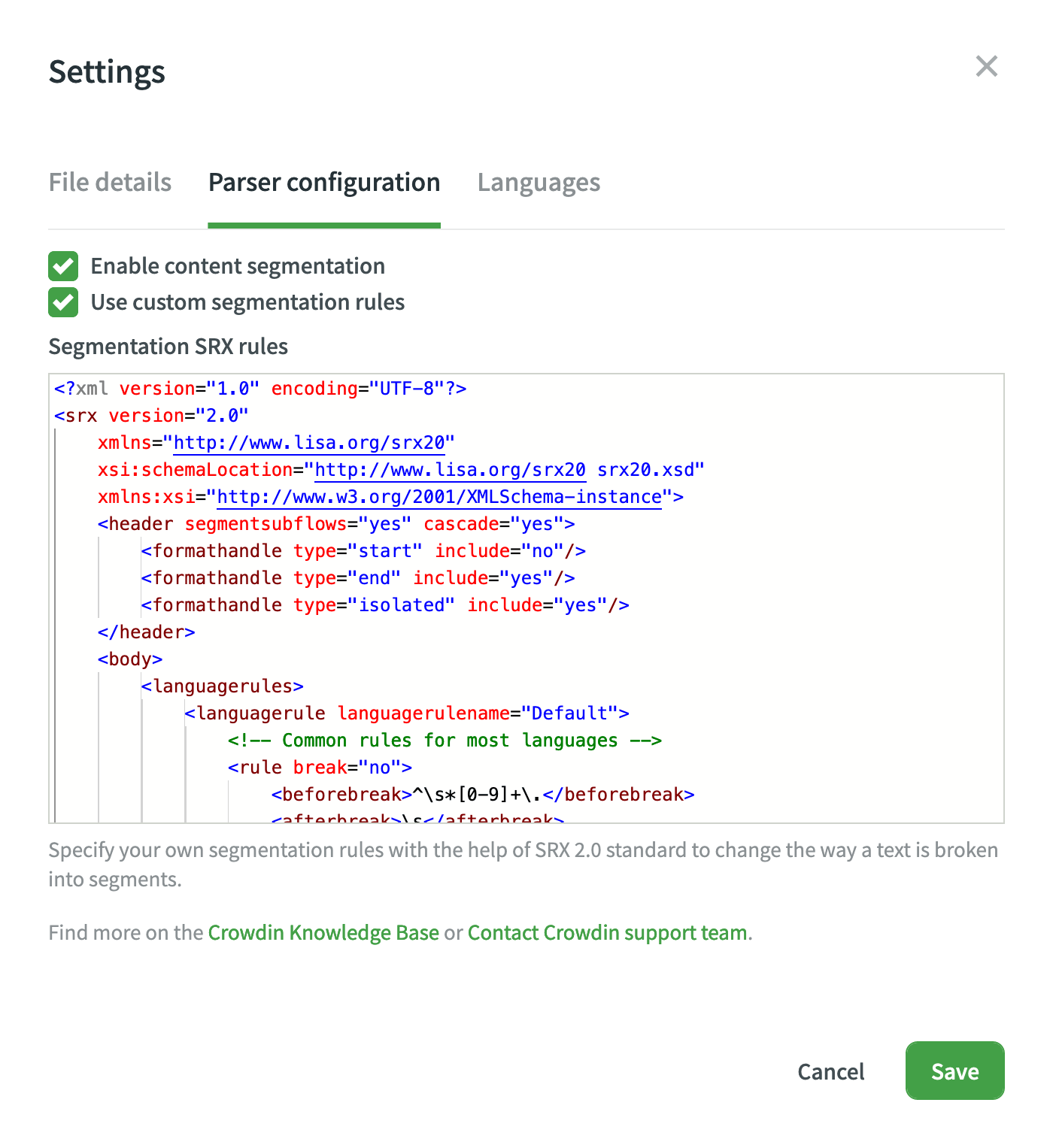
Depois de salvar suas novas regras de segmentação, seu arquivo de origem será automaticamente reimportado e segmentado de acordo com essas novas regras.
Exemplos de Segmentação
Note: Regular expressions used in SRX rules must be compatible with PHP (PCRE2) and Node.js.
Um arquivo SRX típico é semelhante ao seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<srx version="2.0"
xmlns="http://www.lisa.org/srx20"
xsi:schemaLocation="http://www.lisa.org/srx20 srx20.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<header segmentsubflows="yes" cascade="yes">
<formathandle type="start" include="no"/>
<formathandle type="end" include="yes"/>
<formathandle type="isolated" include="yes"/>
</header>
<body>
<languagerules>
<languagerule languagerulename="Default">
<!-- Common rules for most languages -->
<rule break="no">
<beforebreak>^\s*[0-9]+\.</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="yes">
<afterbreak>\n</afterbreak>
</rule>
<rule break="yes">
<beforebreak>[\.\?!]+</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
</languagerule>
</languagerules>
<maprules>
<!-- List exceptions first -->
<languagemap languagepattern="[Ee][Nn].*" languagerulename="English"/>
<languagemap languagepattern="[Ff][Rr].*" languagerulename="French"/>
<!-- Japanese breaking rules -->
<languagemap languagepattern="[Jj][Aa].*" languagerulename="Japanese"/>
<!-- Common breaking rules -->
<languagemap languagepattern=".*" languagerulename="Default"/>
</maprules>
</body>
</srx>Alterar Separador de Frases para Idiomas Asiáticos
Normalmente, o ponto final é usado como separador de frase. Embora, para alguns idiomas asiáticos, não seja o caso. Por exemplo, o separador de frase típico em chinês é um ponto final ideográfico (。). Para tais casos, você pode querer usar o seguinte conjunto de regras:
<rule break="yes">
<beforebreak>[\x3002]+</beforebreak>
<afterbreak></afterbreak>
</rule>Dividir o Texto em Partes Menores
Na frase simples a seguir, detalharemos um caso em que é necessário segmentar uma parte do texto em duas (ou mais) strings.
Texto com regras de segmentação padrão:
Esta é a primeira parte da frase de amostra e esta é a segunda parte.
Texto com novas regras de segmentação:
Esta é a primeira parte da frase de amostra
e esta é a segunda parte.
Para este caso particular, o seguinte conjunto de regras irá quebrar a frase inicial em duas partes:
<rule break="yes">
<beforebreak>frase</beforebreak>
<afterbreak>\u0020</afterbreak>
</rule>Crie Regras de Segmentação com Editores SRX
As regras de segmentação SRX podem ser criadas e mantidas com a ajuda de ferramentas como Ratel. Possui uma interface visual onde você pode gerar regras de segmentação do zero ou editar as existentes.
Procurando Assistência
Precisa de ajuda para definir suas regras de segmentação personalizada ou tem alguma dúvida? Entre em Contato com a Equipe de Suporte.