翻译记忆
翻译记忆 (TM) 是一个存储翻译单元的数据库,翻译单元是源文本的句段及其在不同语言中的对应译文。 它通过为项目中相同或相似的字符串提供建议来改善和加快翻译过程。
每个 Crowdin 项目都会自动创建一个项目翻译记忆。 默认情况下,项目中进行的每一次翻译都会自动添加到该项目的翻译记忆中。 可以在项目设置中自定义此行为,以仅保存已批准的译文。
除了每个项目自动创建的项目翻译记忆之外,您还可以创建单独的翻译记忆,并通过上传 TMX、XLSX 或 CSV 格式的现有翻译记忆来填充内容。 然后可以根据需要将这些翻译记忆分配给相关项目。
创建翻译记忆的步骤如下:
- 打开您的个人资料主页,然后在左侧栏中选择 翻译记忆。
- 单击 创建翻译记忆。

- 在出现的对话框中,为您的翻译记忆命名并选择将在翻译单元表中首先显示的默认语言。
- (可选) 将翻译记忆分配给所需的项目。 您可以跳过此步骤并稍后分配翻译记忆。
- 单击 创建。

您可以从头创建翻译单元,编辑和删除特定翻译记忆或所有可用翻译记忆的现有翻译单元或句段。
要创建翻译单元,请按以下步骤操作:
- 打开您的个人资料主页,然后在左侧栏中选择 翻译记忆。 或者,打开您的项目并转到 设置 > 翻译记忆。
- 选择所需的翻译记忆,然后单击 查看记录。
- 单击 添加翻译单元。

- 在出现的对话框中,从下拉菜单中选择语言并输入该句段的译文。
- 单击 添加句段 为翻译单元添加更多译文。
- 单击 创建。

打开翻译记忆后,您可以使用“翻译单元”或“句段”页面查看和筛选其翻译单元和句段。
在“翻译单元”页面上,您可以查看分组为翻译单元的翻译记忆内容(每行一个翻译单元,每个句段显示在单独的语言列中)。

在“句段”页面上,您可以将翻译记忆内容作为单独的句段(每行一个句段)查看,其详细信息如下:
- 句段 – 包含源语言文本或目标语言文本。
- 语言 – 句段的语言(例如,法语、西班牙语)。
- 使用次数 – 指定某个句段已被使用的次数。
- 创建时间 – 句段首次添加到翻译记忆的日期。
- 最后修改时间 – 句段最近一次编辑的日期。
- 作者 – 将句段添加到翻译记忆的用户。

默认情况下,所有翻译单元和句段均显示在“翻译单元”和“句段”页面中。 要筛选显示的翻译单元或句段,请单击 并使用可用的筛选选项:
- 创建时间:全部、自定义范围。
- 修改于:全部、自定义范围。
- 作者:全部、特定用户。
- 语言(特定于“句段”页面):全部,特定语言。
- 使用情况(特定于“句段”页面):全部、已使用、未使用。
要对翻译单元或句段进行排序,请单击要排序的列标题:
- 翻译单元页面 – 单击语言列(例如,英语、法语等) 按该语言的文本对翻译单元进行排序。
- 句段页面 – 单击“句段”列按句段文本排序。
单击一次以升序排序,再次单击以降序排序。
您可以编辑现有翻译单元的原文部分和译文部分。
要编辑翻译单元,请按以下步骤操作:
- 打开您的个人资料主页,然后在左侧栏中选择 翻译记忆。 或者,打开您的项目并转到 设置 > 翻译记忆。
- 选择所需的翻译记忆,然后单击 查看记录。 或者,单击 所有记录 以在一个列表中查看所有可用翻译记忆的翻译单元。

- 双击打开翻译单元,或单击 编辑。
- 在出现的对话框中,编辑或删除所需语言的句段。 对于每个句段,您可以查看其他详细信息,例如语言、创建日期、最后修改日期,以及(如果可用)最初提交译文的贡献者姓名。
- 点击保存。

除了通过 翻译记忆 页面编辑翻译单元外,您还可以在编辑器中进行编辑。
进一步了解在编辑器中编辑翻译记忆建议。
另一种编辑翻译记忆中翻译单元的方式是将其下载(例如,以 TMX 格式),在本地设备上进行必要的修改,然后将修改后的翻译记忆重新上传到 Crowdin。
根据您在翻译记忆中所做的修改,可能会有不同的结果:
-
如果您同时编辑了翻译单元的源句段和译文句段,那么当您将翻译记忆上传到 Crowdin 时,本地修改后的翻译单元将被视为新单元,原始翻译单元保持不变。
-
如果您仅编辑了翻译单元的译文句段,那么当您将翻译记忆上传到 Crowdin 时,本地修改后的译文句段将作为替代版本句段添加到现有翻译单元中,原始译文保持不变,但提供了另一个选项。
如果您只想保留修改后的翻译单元版本,请按以下步骤操作:
- 将翻译记忆的完整版本下载到您的设备。
- 在本地设备上进行必要的修改。
- 完全清除 Crowdin 中翻译记忆的内容。
- 将本地修改后的翻译记忆上传到 Crowdin。
您可以使用 查找和替换 功能轻松地在选定的翻译记忆中查找和替换句段中的译文。
要用新译文替换当前译文,请按照以下步骤操作:
- 打开您的个人资料主页,然后在左侧栏中选择 翻译记忆。 或者,打开您的项目并转到 设置 > 翻译记忆。
- 选择所需的翻译记忆,然后单击 查看记录。
- 单击 。
- 在出现的对话框中,选择您想要搜索的语言。 (可选) 如有必要,使用筛选器。
- 输入您要替换的单词、短语或句子,以及替换文本。 (可选) 使用 匹配大小写 和 完全匹配 选项来优化搜索结果。
- 单击 查找 可预览将被替换的句段。

- 选择要替换的句段,然后单击 替换所选 即可完成。
您可以一次删除一个、多个或所有翻译单元或句段。
要从翻译记忆中删除所有翻译单元,请按以下步骤操作:
- 在“翻译单元”页面上,选中翻译单元列表上方的复选框。
- 确认选择所有翻译单元。
- 单击 。

要从翻译记忆中删除某一特定语言的所有句段,请按照以下步骤操作:
- 在“句段”页面,单击 并选择所需的语言。
- 选中句段列表上方的复选框。
- 确认所有句段的选择。
- 单击 。

在处理翻译单元和译文的删除时,可能会有三种结果:
- 从翻译记忆中删除翻译单元时,Crowdin 项目中的字符串的相关译文不会被删除。
- 当您通过“活动”选项卡取消字符串的翻译活动时,该字符串的译文将被删除,但相关的翻译单元将保留在翻译记忆中。
- 在编辑器中删除字符串的译文时,译文和相关的翻译单元都将被删除。
若要下载或上传翻译记忆,请遵循以下步骤:
- 打开您的个人资料主页,然后在左侧栏中选择 翻译记忆。 或者,打开您的项目并转到 设置 > 翻译记忆。
- 单击所需翻译记忆上的 查看记录。
- 单击 并选择 下载 或 上传。

项目所有者和管理员可以下载和上传以下文件格式的翻译记忆:TMX、XLSX 或 CSV。
如果以 CSV 或 XLS/XLSX 文件格式上传翻译记忆,请在配置对话框中将对应语言的列匹配起来。

一旦您以 CSV 或 XLSX 格式上传翻译记忆文件,系统会根据第一行指定的列名称自动检测文件架构。 识别以不区分大小写的方式执行。 未自动检测到的列将保留为 未选择,以供手动配置。 当您上传包含多种语言的翻译记忆电子表格时,自动列识别会特别有用。
为了充分利用自动列识别功能,我们建议您使用以下值命名 CSV 或 XLSX 翻译记忆文件中的语言列:
- 语言名称(例如,Ukrainian)
- Crowdin 语言代码(例如,uk)
- 语言区域(例如,uk-UA)
- 带下划线的区域设置(例如:uk_UA)
- ISO 639-1 语言代码(例如,uk)
- ISO 639-2/T 语言代码(例如,ukr)
要重新检测翻译记忆文件架构,请单击 检测配置。
当从 Crowdin 下载 TMX 格式的翻译记忆时,您可以获得一些额外的元数据,这些元数据可能对于离线工具的不同使用场景有用。
以 TMX 格式下载的翻译记忆提供的其他翻译记忆属性:
x-crowdin-metadata– 字符串标识符哈希值。creationid– 译文作者在 Crowdin 中的全名和用户名。creationdate– 译文最初创建的日期。changeid– 更新译文的人员的全名和用户名。changedate– 译文最后更新的日期。usagecount– 翻译建议在 Crowdin 中的使用次数。lastusagedate– 在 Crowdin 中最后一次使用翻译建议的日期。
在 Crowdin 工作的翻译供应商通常会从项目中导出翻译记忆,以便在各种桌面应用程序中为他们的客户进行管理(例如,清除不相关的译文的翻译记忆并进一步重新导入回 Crowdin)。 上面列出的翻译记忆属性允许根据不同的标准更好地导航和筛选翻译记忆句段。 此外,您可以使用清理和刷新后的翻译记忆仅针对特定于产品的数据来训练机器翻译引擎,从而确保更高的翻译质量。
使用共享的翻译记忆,您可以自动翻译您拥有的任何项目。 此外,所有翻译记忆中的翻译记忆建议都将显示在编辑器中。
要在您拥有的所有项目之间共享翻译记忆,请按照以下步骤操作:
- 打开您的个人资料主页,然后在左侧栏中选择 翻译记忆。
- 选择 共享翻译记忆。

通过翻译记忆进行自动翻译可让您利用至少 100% 匹配和完美匹配。
在通过翻译记忆进行自动翻译时,系统会考虑多个参数来选择最相关的翻译记忆建议。 如果系统只为某个字符串找到一个合适的翻译记忆建议,该建议将在通过翻译记忆进行自动翻译时被应用。 如果系统为某个字符串找到两个或更多翻译记忆建议,它们将根据多个参数进行排序,并应用最合适的一个。
以下参数按系统用于判断哪个翻译记忆建议更合适的顺序列出。 如果无法使用第一个参数做出决定(即两个翻译记忆建议均为 100% 匹配),系统将使用下一个参数,直至做出决定。
- 相关性 – 也称为翻译记忆匹配度。 进一步了解翻译记忆匹配计算。
- 自动替换使用情况 – 验证翻译记忆建议是否通过自动替换得到改进。 进一步了解自动替换。
- 已分配的翻译记忆优先级 – 存储翻译记忆建议的翻译记忆的优先级。 进一步了解翻译记忆优先级设置。
- 主要语言或方言语言 – 翻译记忆建议源文本中使用的主要语言或方言语言(例如,来自英语的翻译记忆建议优先级高于加拿大英语)。
- 翻译记忆建议创建日期 – 翻译记忆建议的创建日期(创建日期较近的翻译记忆建议优先级更高)。
为了更好地了解在通过翻译记忆进行自动翻译时翻译记忆建议的优先级排序方式,我们来看几个假设场景。 假设您的项目中有一个未翻译的字符串,其源文本为 Welcome!。 一旦您运行通过翻译记忆进行的自动翻译,系统就会开始在您的翻译记忆中搜索翻译记忆建议。
- 系统找到两个翻译记忆建议,其源文本分别为
Welcome和Welcome!。 由于Welcome!翻译记忆建议具有更高的翻译记忆匹配度,因此将使用该建议的译文。 - 系统找到两个翻译记忆建议:
Welcome!和Welcome!。 两者源文本相同,因此系统检查这些翻译记忆建议是否通过自动替换得到改进,并选择未经自动替换改进的那个。 - 系统找到两个翻译记忆建议:
Welcome!和Welcome!。 两者源文本相同,且均未经自动替换改进。 然后系统检查这些翻译记忆建议所在翻译记忆的优先级,并选择存储在优先级较高的翻译记忆中的那个。 - 系统找到两个翻译记忆建议:
Welcome!和Welcome!。 两者源文本相同,均未经自动替换改进,且均存储在优先级相同的翻译记忆中。 然后系统检查翻译记忆建议的源语言,并选择使用主要语言的那个。 - 系统找到两个翻译记忆建议:
Welcome!和Welcome!。 两者源文本相同,均未经自动替换改进,均存储在优先级相同的翻译记忆中,且均使用主要源语言。 然后系统检查翻译记忆建议的创建日期,并选择日期最新的那个。
在极少数情况下,可能会出现两个或更多翻译记忆建议在上述所有参数上均完全相同的情况。 在这种情况下,系统会选择相同建议中的第一个。
为了提高准确性,Crowdin 在确定翻译记忆匹配时会尽量降低 HTML 标签的影响。 匹配不是基于原始字符串进行的,而是在将 HTML 标签替换为占位符的字符串上进行匹配,与编辑器中的行为类似。
例如,字符串 Hello <b>world</b>! 与字符串 Hello <a href='#'>world</a>! 将达到 100% 匹配。
当启用方言语言的翻译记忆建议选项时,Crowdin 将在编辑器中为方言语言显示来自主要语言的翻译记忆建议。 例如,如果您的目标语言为西班牙语和西班牙语(阿根廷),且该选项已启用,编辑器将在“翻译记忆和 MT 建议”部分显示来自西班牙语的翻译记忆建议,用于西班牙语(阿根廷)(在翻译记忆和 MT 建议部分显示为“英语 -> 西班牙语”)。
但是,此行为不适用于 搜索翻译记忆 功能。 如果您在使用方言语言时,通过“搜索翻译记忆”标签页搜索来自主语言的翻译记忆建议,将不会找到任何结果。
Crowdin 通过比较要翻译的源字符串和翻译记忆现有的句段来计算翻译记忆匹配。
翻译记忆匹配主要有三种类型:
- 完美匹配 - 翻译记忆句段的文本和语境与源字符串完全匹配
- 100% 匹配 - 翻译记忆句段的文本与源字符串匹配,但上下文不同
- 模糊匹配(99% 及以下)- 翻译记忆句段的文本与源字符串在一定程度上有所不同
如果完美和 100% 翻译记忆匹配的计算相对简单,则模糊匹配的计算可能就不那么明显了。
影响模糊匹配计算的因素有多种,例如:
- 词序
- 标点
- 格式化标签
- 匹配长度比源字符串长
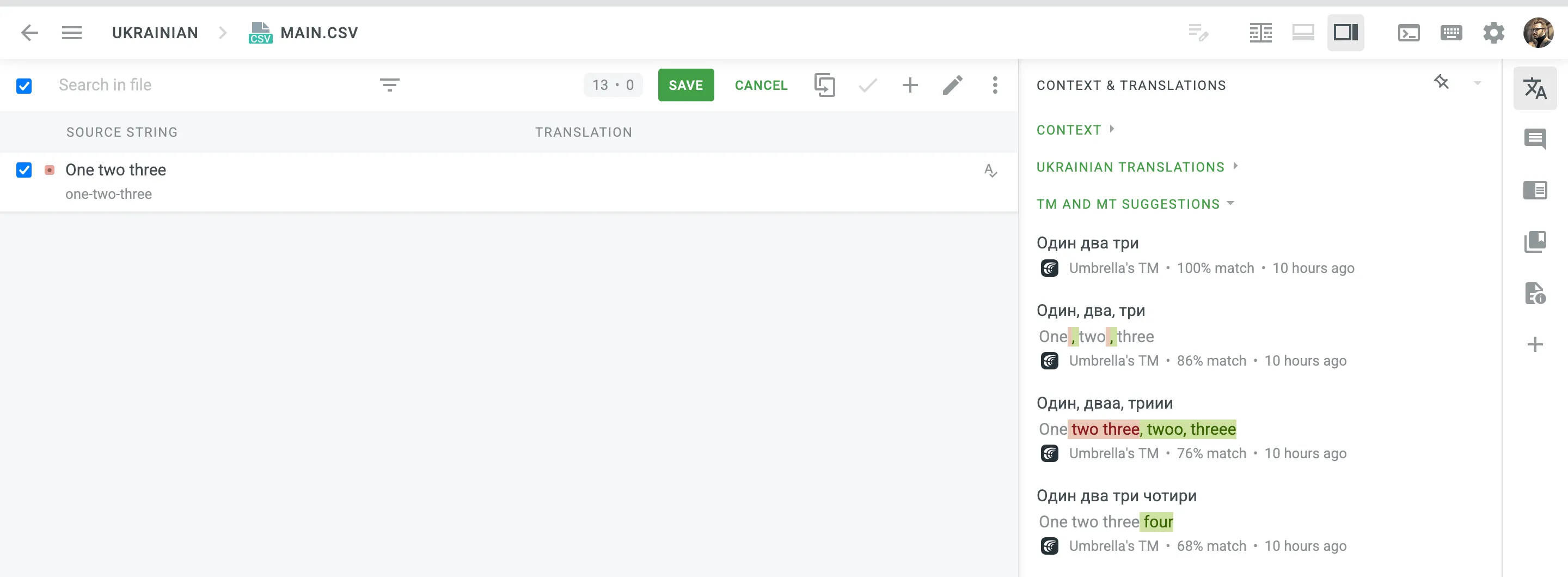
自动替换旨在通过建议具有更高相似度匹配的译文,提升使用翻译记忆(翻译记忆)的效益。 该功能将翻译记忆建议的译文中的不可翻译元素(如标签、HTML 实体、占位符、数字等)替换为源字符串中使用的对应元素。
要启用自动替换功能,请打开您的项目并转到 设置 > 翻译记忆。
自动替换功能可替换以下不可翻译元素:
| Non-translatable elements | Source string example | TM suggestion (German) | Improved TM suggestion |
|---|---|---|---|
| Tags | <b %s>Help</b> | <span>Hilfe<span> | <b %s>Hilfe</b> |
| HTML entities | Currency € | Währung ¥ | Währung € |
| Line breaks | Profile | Profil<br/> | Profil |
| Escape sequences (\r\n, \r, \n, \t, unicode, hex) | Translation \x42 | Übersetzung \u4242 | Übersetzung \x42 |
| Non-escaped equivalents of \r\n, \r, \n, \t | Translated by \n TM | Übersetzt vom Übersetzungsspeicher | Übersetzt vom \n Übersetzungsspeicher |
| Placeholders | Example %s | Beispiel %1$s | Beispiel %s |
| Numbers | Attempt 2 | Versuch 5 | Versuch 2 |
| Letter case | Log in | einloggen | Einloggen |
| Special characters | Help? | Hilfe! | Hilfe? |
| URLs | More Information: https://crowdin.com/features | Weitere Infos: https://crowdin.com/ | Weitere Infos: https://crowdin.com/features |
| ICU syntax | Get {discountPercent, number, percent} discount | Erhalte {discountValue, number, currency} Rabatt | Erhalte {discountPercent, number, percent} Rabatt |
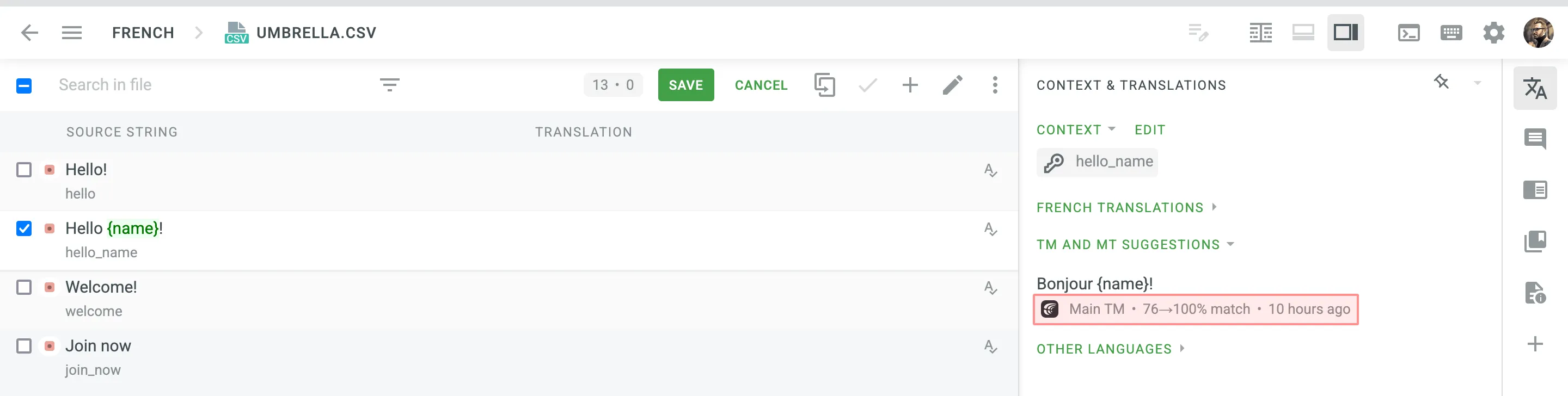
启用翻译记忆自动替换后,您可以在自动翻译过程中利用改进后的翻译记忆建议。 请确保将最低匹配率设置为 100%。 这将使结果包含 100% 翻译记忆匹配以及通过翻译记忆自动替换改进至 100% 的匹配。
借助自动替换功能,译员可以在编辑器中看到改进后的翻译记忆建议。 改进后的建议下方显示的百分比表示原始翻译记忆建议和改进后建议的匹配百分比。
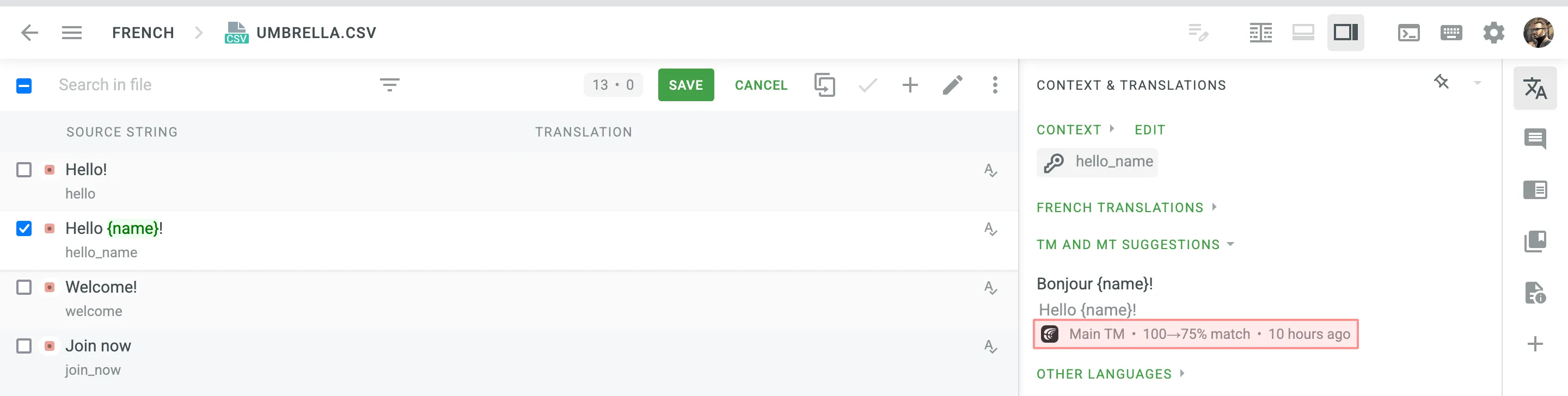
在某些情况下,您可能希望根据特定条件对翻译记忆建议应用惩罚以降低其匹配百分比。
例如,您可以为通过自动替换功能改进的翻译记忆建议设置惩罚,以优先采用精确匹配而非改进匹配。 改进后且受惩罚的建议下方显示的百分比表示改进后的翻译记忆建议和受惩罚建议的匹配百分比。 将光标悬停在百分比上可查看更多详情。
进一步了解翻译记忆建议惩罚设置。
费用估算报告会根据自动替换功能可将字符串改进到的最高相似度匹配,统计潜在可被改进的翻译记忆建议。 例如,可以从 75% 匹配提升至 100% 匹配的匹配将被视为 100% 匹配。
翻译费用报告会将通过自动替换功能改进的翻译记忆建议作为常规翻译记忆建议进行统计。 例如,从 75% 匹配改进至 100% 匹配的匹配将被视为 100% 匹配。